Which is fastest? ERB vs. HAML vs. Slim
In this article, we’ll test and analyze the performance of three most popular Ruby templating engines: ERB (the default one), HAML, and SLIM.
Benchmarking is the practice of comparing business processes and performance metrics to industry bests and best practices from other companies. Meanwhile, load testing is the process of putting demand on a system and measuring its response.
Our goal is to explore a little bit of the Ruby Benchmark module, which provides methods to measure and report the time used to execute Ruby code. We’ll create some inline templates, run them against the tests, and extract metrics over the three different engines.
After that, we'll dive into load testing by creating some real-world template views, put them live on the server, and then perform some load tests via the hey tool. It provides us with some great features to send loads to a specific web application and get thorough data related to how each endpoint and, hence, each template engine is performing.
Setup
The first thing to do, of course, is to make sure you already have Ruby installed. We’re using the most recent version, 2.7.0, as of the writing of this article. Make sure to also install the Rails gem.
Ruby and the Rails gem are pretty much what we need to get started. For this tutorial, Visual Studio Code is the IDE for coding, but feel free to pick another if you prefer.
Now, choose a folder for our Rails project and run the following command:
rails new haml-slim-erb
This will download all the required dependencies and create our scaffolded Rails project. Go ahead and explore it.
Before proceeding to the code, we need to add the SLIM and HAML dependencies to our Gemfile:
group :development, :test do
# Call 'byebug' anywhere in the code to stop execution and get a debugger console
gem 'byebug', platform: :mri
gem 'haml'
gem 'slim'
end
There’s also a bug that comes by default with the project that’s related to the SQLite version. Locate it in the Gemfile and change it to the following:
gem 'sqlite3', '~> 1.3.0'
Now, run the bundle install command to download the dependencies.
Exploring the Benchmark Module
For this part of the article, we’ll be working directly with the test folder. Open it, and you’ll see some empty folders. Let’s create a new one called benchmark and three other files: example_1_test.rb, example_2_test.rb, and example_3_test.rb..
Ruby needs that t end with test to be considered a test file.
Next, add the following content to the first file:
require 'benchmark'
number = (0..50).to_a.sort{ rand() - 0.5 }[0..10000]
puts Benchmark.measure {
20_000.times do
number[rand()] * (0..50).to_a.sort{ rand() - 0.5 }[0..10000][rand()]
end
}
Note that the first line imports the required Benchmark module. Then, we generate a random array of numbers from 0 to 50 with 10.000 of size. These big numbers are just to take some time in processing.
The method measure is very useful because it can be placed anywhere in your Ruby code to measure how much time it’s taking to process. This time is returned and printed by the puts.
Inside, we’re looping for 20k times the execution of the same random-generated array to multiply one value of each.
To run this test file specifically, issue the following command:
rake test TEST=test/benchmark/example_1_test.rb
The result may look like this:
0.702647 0.012353 0.715000 ( 0.721910)
This report prints, respectively, the user CPU time, the system CPU time, the sum of the user and system CPU times, and the elapsed real-time. The unit of time is seconds.
We’ll make use of the other Benchmark methods further in practice.
Inline Templates Testing
Now that you understand a bit more about how Ruby’s Benchmark module works, we’ll dive into the execution of some tests over the three templates.
For this, we’ll create a single template, translate it into the three engine syntax, and finally, run it under the Benchmark method.
Add the following to the second test file:
require 'erb'
require 'haml'
require 'slim'
require 'benchmark'
require 'ostruct'
notes = OpenStruct.new title: 'Write an essay', description: 'My essay is about...', randomList: (0..50).to_a.sort{ rand() - 0.5 }[0..10000]
erb_example = <<-ERB_EXAMPLE
<span><%= notes.title %></span>
<span><%= notes.description %></span>
<table>
<tr>
<% notes.randomList.each do |note| %>
<td><%= note %></td>
<% end %>
</tr>
</table>
ERB_EXAMPLE
slim_example = <<-SLIM_EXAMPLE
span= notes.title
span= notes.description
table
tr
- notes.randomList.each do |note|
td= note
SLIM_EXAMPLE
haml_example = <<-HAML_EXAMPLE
%span= notes.title
%span= notes.description
%table
%tr
- notes.randomList.each do |note|
%td= note
HAML_EXAMPLE
context = OpenStruct.new notes: notes
__result = ''
Benchmark.bmbm(20) do |bcmk|
bcmk.report("erb_test") { (1..2000).each { ERB.new(erb_example, 0, '-', '__result').result binding } }
bcmk.report("slim_test") { (1..2000).each{ __result = Slim::Template.new { slim_example }.render(context) } }
bcmk.report("haml_test") { (1..2000).each { __result = Haml::Engine.new(haml_example).render(binding) } }
end
First, import the required modules. Other than the template engines, we’re also importing the ostruct module. An OpenStruct is a data structure from metaprogramming, similar to a Hash, that allows the definition of arbitrary attributes with their accompanying values.
It is useful because we don’t need to create a whole class structure to store the values. We can define it inline.
Our struct is basically a Note object with a title, description, and a list of random numbers, which increase processing time.
We won’t focus on how each template engine works; you can refer to their official docs for this. However, their syntax is pretty easy to assimilate.
The magic is placed at the end of the code. Now, we’re using the bmbm method, which does a bit more than the first one. Sometimes, benchmark results may be skewed due to external factors, such as garbage collection, memory leaks, etc. This method attempts to minimize this effect by running the tests twice: the first time as a rehearsal to get the runtime environment stable and the second time for real. You can read more on this here.
Finally, each one of the bmbm’s inner code lines executes a loop 2000 times during the creation of each template. The focus is on assigning the template and rendering it.
After executing this test file, here’s the result:
Rehearsal --------------------------------------------------------
erb_test 0.311534 0.002963 0.314497 ( 0.314655)
slim_test 2.544711 0.004520 2.549231 ( 2.550307)
haml_test 1.449813 0.003169 1.452982 ( 1.454118)
----------------------------------------------- total: 4.316710sec
user system total real
erb_test 0.298730 0.000679 0.299409 ( 0.299631)
slim_test 2.550665 0.004148 2.554813 ( 2.556023)
haml_test 1.432653 0.001984 1.434637 ( 1.435417)
The two result blocks are separated for you to assimilate what’s real from the rehearsal.
Changing the Scenario a Bit
For the last test results, you could assume that ERB is the best option, while SLIM is the worst. Again, it depends on the situation.
In that test, every time we loop, we have to instantiate a new template engine object. This is not an optimal flow.
Let’s change it slightly and move this instantiation to the outside, as shown in the following code snippet:
erb_engine = ERB.new(erb_example, 0, '-', '__result')
slim_engine = Slim::Template.new { slim_example }
haml_engine = Haml::Engine.new(haml_example)
Benchmark.bmbm(10) do |bcmk|
bcmk.report("erb_test") { (1..2000).each { erb_engine.result binding } }
bcmk.report("slim_test") { (1..2000).each{ __result = slim_engine.render(context) } }
bcmk.report("haml_test") { (1..2000).each { __result = haml_engine.render(binding) } }
end
The code does exactly the same as before. Now, run the tests again, and you’ll see something like this as a result:
Rehearsal ----------------------------------------------
erb_test 0.127599 0.002407 0.130006 ( 0.130137)
slim_test 0.046972 0.000841 0.047813 ( 0.047858)
haml_test 0.208308 0.002239 0.210547 ( 0.210769)
------------------------------------- total: 0.388366sec
user system total real
erb_test 0.118002 0.000556 0.118558 ( 0.118618)
slim_test 0.040129 0.000090 0.040219 ( 0.040320)
haml_test 0.205331 0.001163 0.206494 ( 0.206680)
Notice which one is the best and the worst now. This is just to show that there is no silver bullet in terms of a perfect engine.
You must test and analyze which features perform better for your style of coding. Plus, there are other auxiliary tools, such as Ruby Profiler, that you can use to understand better how and why the code behaves this way.
Load Testing a Real-World Scenario
Let’s move on to something closer to our reality. We’re going to benchmark a real template that lists some notes (three, one for each template engine).
Since the benchmark module takes place in the Rails code, we lose some important measures related to the template engine internal processes.
This type of benchmark test allows us to see how each engine performs as a whole, from the very beginning of the process via the arrival of a request, to the business logic processing until the response data gets to the views. This last one, specifically, will have a bunch of steps, such as the parsing and rendering processes that the load test can measure, and the benchmark cannot.
First, let’s create the Rails controllers for each example:
rails g controller notes_erb index
rails g controller notes_haml index
rails g controller notes_slim index
This command will auto-generate a bunch of common Rails files you may be used to.
Next, let’s open the notes_erb_controller.rb created file and change its content to:
class NotesErbController < ApplicationController
def index
@notes = JSON.parse(Constants::NOTES, object_class: OpenStruct)
end
end
Here’s where we feed the templates with data. Note that we have one controller class for each of the engines.
Basically, we’re grabbing some JSON from an inline constant. The response is going to be parsed into a new OpenStruct object and returned to the engines.
The NOTES constant must be placed into a new file called constants.rb. Go ahead and create it, and then add the following content:
class Constants
NOTES = '[
{
"title": "Walk the dog",
"description": "Bla bla",
"tasks": [{
"title": "Task #1"
},
{
"title": "Task #2"
},
{
"title": "Task #3"
}]
},
...
{
"title": "Walk the dog",
"description": "Bla bla",
"tasks": [{
"title": "Task #1"
},
{
"title": "Task #2"
},
{
"title": "Task #3"
}]
}
]
'
end
Please, make sure to change the ellipsis for more note elements. Plus, don’t forget to replicate the logic in each one of the other controllers.
Creating the ERB Views
Now, it’s time to create the views of our example. To do so, go to the views/notes_erb folder and create two other files: note.html.erb and task.html.erb. They’ll help us build an example that contains views, partials, and layouts.
This way, we guarantee our example explored the Rails engines the most. Make sure to create files equivalent to both views/notes_haml and views/notes_slim.
Let’s start with the index.html.erb code:
<style>
h2 {
text-align: center;
}
table, td, th {
border: 1px solid #ddd;
text-align: left;
}
table {
border-collapse: collapse;
width: 80%;
margin: auto;
}
th, td {
padding: 15px;
}
</style>
<h2>List of Notes</h2>
<table>
<thead>
<tr>
<th>Title</th>
<th>Description</th>
<th>Tasks</th>
</tr>
</thead>
<tbody>
<%= render partial: 'notes_erb/note', collection: @notes %>
</tbody>
</table>
There's nothing too special here. Note that we’re importing a partial, the _note.html.erb file, and passing a collection parameter: our @notes previously created in the controller.
Here’s the note’s content, by the way:
<tr>
<td>
<span><%= note.title %></span>
</td>
<td>
<span><%= note.description %></span>
</td>
<td>
<ul>
<%= render partial: 'notes_erb/task', collection: note.tasks %>
</ul>
</td>
</tr>
Here's another partial, accessing the tasks array this time.
The content for the _task.html.erb is the following:
<li><%= task.title %></li>
HAML’s Views
You will notice that the syntax from one engine to another is very similar. What changes is just the verbosity of each one. SLIM, for example, is the cleanest one among them.
Take a look at the code for the three files:
# Content of index.html.haml
:css
h2 {
text-align: center;
}
table, td, th {
border: 1px solid #ddd;
text-align: left;
}
table {
border-collapse: collapse;
width: 80%;
margin: auto;
}
th, td {
padding: 15px;
}
%h2 List of Notes
%table
%thead
%tr
%th Title
%th Description
%th Tasks
%tbody
= render partial: 'notes_haml/note', collection: @notes
# Content of _note.html.haml
%tr
%td
%span= note.title
%td
%span= note.description
%td
%ul
= render partial: 'notes_haml/task', collection: note.tasks
# Content of _task.html.haml
%li= task.title
Very similar, isn't it?
SLIM’s Views
Finally, we have SLIM's views. Here’s the greatest difference from the other two ones. The whole structure becomes clearer:
# index.html.slim
css:
h2 {
text-align: center;
}
table, td, th {
border: 1px solid #ddd;
text-align: left;
}
table {
border-collapse: collapse;
width: 80%;
margin: auto;
}
th, td {
padding: 15px;
}
h2 List of Notes
table
thead
tr
th Title
th Description
th Tasks
tbody
= render partial: 'notes_haml/note', collection: @notes
# _note.html.slim
tr
td
span= note.title
td
span= note.description
td
ul
= render partial: 'notes_haml/task', collection: note.tasks
# _task.html.slim
li= task.title
You’ll also have to translate the layouts to each respective engine syntax. Two new files have to be created under the views/layouts folder: application.html.haml and application.html.slim.
I’ll leave that job to you as homework. However, if you find it difficult, you can consult my version in the GitHub project link available at the end of the article.
Running the Tests
Finally, we get to test the example. First, start up the application by running the rails s command. It’ll start at the http://localhost:3000/ address.
Here’s what the view will look like:
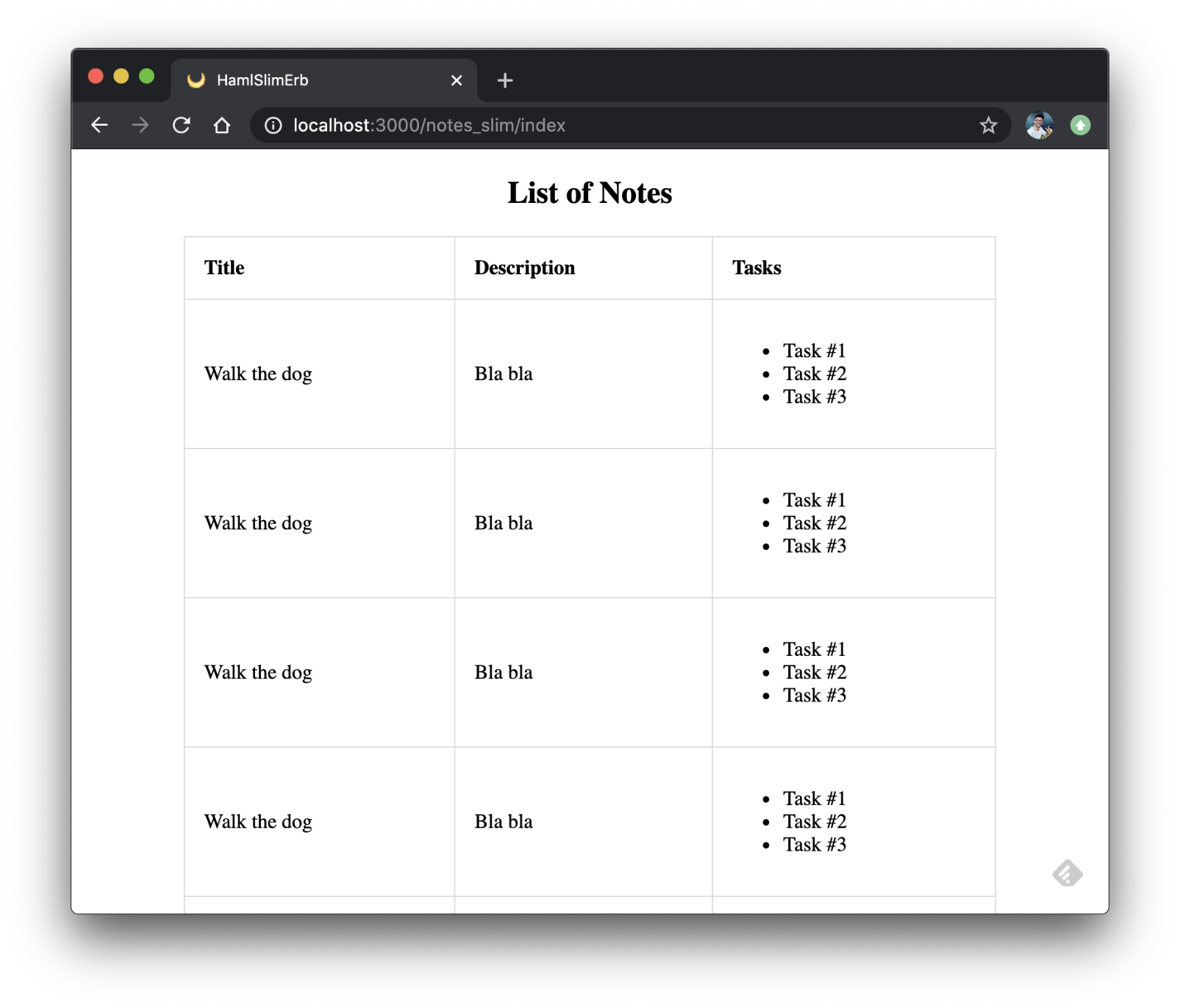
Each template engine example will be available at its respective URL auto-generated in the config/routes.rb file.
To benchmark test these examples, we’ll make use of the hey benchmark tool. It is very simple and provides some useful information for benchmark analysis. These are the commands:
$ hey http://localhost:3000/notes_erb/index
Summary:
Total: 9.3978 secs
Slowest: 9.1718 secs
Fastest: 0.0361 secs
Average: 1.2714 secs
Requests/sec: 21.2816
$ hey http://localhost:3000/notes_haml/index
Summary:
Total: 10.8661 secs
Slowest: 10.2354 secs
Fastest: 0.1871 secs
Average: 1.4735 secs
Requests/sec: 18.4058
$ hey http://localhost:3000/notes_slim/index
Summary:
Total: 11.3384 secs
Slowest: 10.7570 secs
Fastest: 0.0437 secs
Average: 1.5406 secs
Requests/sec: 17.6392
As you can see, all the engines are very close in terms of execution time. The default number of requests to run is 200, but you can change this value via the -n option.
Let's take a look at the same tests performed with 1200 requests:
$ hey -n 1200 http://localhost:3000/notes_erb/index
Summary:
Total: 52.2586 secs
Slowest: 19.2837 secs
Fastest: 0.0389 secs
Average: 0.6960 secs
Requests/sec: 22.9627
$ hey -n 1200 http://localhost:3000/notes_haml/index
Summary:
Total: 61.7637 secs
Slowest: 18.5290 secs
Fastest: 0.0442 secs
Average: 0.8557 secs
Requests/sec: 19.4289
$ hey -n 1200 http://localhost:3000/notes_slim/index
Summary:
Total: 63.1625 secs
Slowest: 19.9744 secs
Fastest: 0.0874 secs
Average: 0.7959 secs
Requests/sec: 18.9986
When you increase the number of concurrent requests, you'll see differences in total and average processing times increase. Obviously, this scenario, with thousands of parallel requests, is very specific and not very common. However, load testing is all about that, taking the endpoints to the limits.
The hey tool also prints other information, such as a response time histogram:
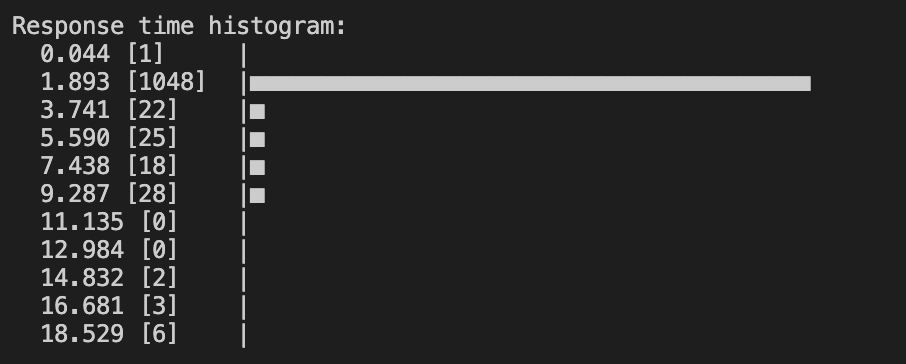
It shows the average time each request took to complete in approximate terms. In our example, it’s clear that most of the requests (1048) were completed in 1.893 seconds. This is why it's desirable to perform stress tests at the same time.
There’s also more info about latency distribution, details over the DNS dialup and lookup, request writing, waiting and reading times, errors, etc.
Check the docs for more custom options/results.
Summary
You can find the source code for this example here.
This kind of test is great for helping you define which template engine may be more suitable for your project needs. As we’ve seen, be careful about poorly implemented code since some small code snippets can abruptly change the overall performance of your execution.
Another interesting point is that ERB, as the default Rails engine, is great at its job too. Besides the other engines being faster in some of our tests, ERB is always close enough to prove its value.
Finally, I’d recommend that you consider some other important factors in the tests as a homework task, including caching, proxy, the usage of databases, and other storing mechanisms, as well as queues and any such tool of an async nature. These items always play an important role in the way your views behave or the processing time it takes to render them. Good luck!

Written by
Diogo SouzaDiogo is a more of an explorer than a programmer. Most of the best discoveries are made prior to the code itself. if free_time > 0 read() draw() eat() end