SOLID Design Principles in Ruby
All software applications change over time. Changes made to software can cause cascading issues that are unexpected. However, change is unavoidable, as we cannot build software that does not change. The software requirements continue changing as the software grows. What we can do is design software in such a way that it is resilient to change. Designing software properly can take time and effort at the start, but in the long-term, it saves time and effort. Tightly coupled software is fragile, and we cannot predict what happens with change. Here are some of the effects of poorly designed software:
- It causes immobility.
- Changing code is expensive.
- It is easier to add more complexity than to make the software simpler.
- The code is unmanageable.
- It takes a lot of time for a developer to figure out how its functionalities work.
- Changing one part of the software usually breaks the other, and we cannot predict what issues a change can bring.
The paper Design Principles and Design Patterns, lists the following symptoms of rotting software:
- Rigidity: It is very difficult to change code without causing problems, as making changes in one part prompts the need to make changes in other parts of the code.
- Fragility: Changing code usually breaks the behavior of the software. It can even break parts that are not directly related to the change.
- Immobility: Although some parts of a software application may have similar behavior, we are unable to reuse the code and must duplicate them.
- Viscosity: When the software is difficult to change, we keep adding complexity to the software instead of making it better.
It is necessary to design software in such a way that changes can be controlled and predictable.
SOLID design principles help resolve these issues by decoupling software programs. Robert C. Martin introduced these concepts in his paper titled Design Principles and Design Patterns, and Michael Feathers came up with the acronym later.
The SOLID design principle includes these five principles:
- Single Responsibility Principle
- Open/Closed Principle
- Liskov Substitution Principle
- Interface Segregation Principle
- Dependency Inversion Principle
We will explore each of them to understand how these principles can help build well-designed software in Ruby.
Single Responsibility Principle - SRP
Let us say that for HR management software, we need the functionality to create users, add the salary of an employee, and generate a payslip of an employee. While building it, we could add these functionalities to a single class, but this approach causes unwanted dependency among these functionalities. It is simple when we start, but when things change and new requirements arise, we will be unable to predict which functionalities the change would break.
A class should have one, and only one reason to change - Robert C Martin
Here's a sample code where all the functionality is in a single class:
class User
def initialize(employee, month)
@employee = employee
@month = month
end
def generate_payslip
# Code to read from database,
# generate payslip
# and write it to a file
self.send_email
end
def send_email
# code to send email
employee.email
month
end
end
To generate a payslip and send it to the user, we can initialize the class and call the generate payslip method:
month = 11
user = User.new(employee, month)
user.generate_payslip
Now, there is a new requirement. We want to generate the payslip but do not want to send the email. We need to keep the existing functionality as it is and add a new payslip generator for internal reporting without sending an email, as it is for internal propose. During this phase, we want to ensure the existing payslip sent to employees remains functional.
For this requirement, we cannot reuse the existing code. We either need to add a flag to the generate_payslip method saying if true send email else don't. This can be done, but since it changes the existing code, it might break the exiting functionality.
To make sure we do not break things, we need to decouple these logics into separate classes:
class PayslipGenerator
def initialize(employee, month)
@employee = employee
@month = month
end
def generate_payslip
# Code to read from database,
# generate payslip
# and write it to a file
end
end
class PayslipMailer
def initialize(employee)
@employee = employee
end
def send_mail
# code to send email
employee.email
month
end
end
Next, we can initialize these two classes and call their methods:
month = 11
# General Payslip
generator = PayslipGenerator.new(employee, month)
generator.generate_payslip
# Send Email
mailer = PayslipMailer.new(employee, month)
mailer.send_mail
This approach helps to decouple the responsibilities and ensures a predictable change. If we only need to change the mailer functionality, we can do that without changing the report generation. It also helps to predict any changes in functionality.
Suppose we need to change the format of the month field in the email to Nov instead of 11. In this case, we will modify the PayslipMailer class, and this will ensure that nothing will change or break in the PayslipGenerator functionality.
Every time you write a piece of code, ask a question afterward. What is the responsibility of this class? If your answer has an "and" on it, beak the class into multiple classes. Smaller classes are always better than large, generic classes.
Open/Closed Principle - OCP
Bertrand Meyer originated the open/closed principle in his book titled Object-Oriented Software Construction.
The principle states, "software entities (classes, modules, functions, etc.) should be open for extension but closed for modification". What this means is that we should be able to change behavior without changing the entity.
In the above example, we have payslip-sending functionality for an employee, but it is very generic for all employees. However, a new requirement arises: generate a payslip based on the type of employee. We need different payroll generation logic for full-time employees and contractors. In this case, we can modify the existing PayrollGenerator and add these functionalities:
class PayslipGenerator
def initialize(employee, month)
@employee = employee
@month = month
end
def generate_payslip
# Code to read from database,
# generate payslip
if employee.contractor?
# generate payslip for contractor
else
# generate a normal payslip
end
# and write it to a file
end
end
However, this is a bad patter. In doing so, we are modifying the existing class. If we need to add more generation logic based on employee contracts, we need to modify the existing class, but doing so violates the open/closed principle. By modifying the class, we risk making unintended changes. When something changes or is added, this might cause unknown issues in the existing code. These if-else can in more places within the same class. So, when we add a new employee type, we might miss places where these if-else are present. Finding and modifying them all can be risky and could create a problem.
We can refactor this code in such a way that we can add functionality by extending the functionality but avoid changing the entity. So, let us create a separate class for each of these and have the same generate method for each of them:
class ContractorPayslipGenerator
def initialize(employee, month)
@employee = employee
@month = month
end
def generate
# Code to read from the database,
# generate payslip
# and write it to a file
end
end
class FullTimePayslipGenerator
def initialize(employee, month)
@employee = employee
@month = month
end
def generate
# Code to read from the database,
# generate payslip
# and write it to a file
end
end
Make sure these have the same method name. Now, change the PayslipGenerator class to use these classes:
GENERATORS = {
'full_time' => FullTimePayslipGenerator,
'contractor' => ContractorPayslipGenerator
}
class PayslipGenerator
def initialize(employee, month)
@employee = employee
@month = month
end
def generate_payslip
# Code to read from database,
# generate payslip
GENERATORS[employee.type].new(employee, month).generate()
# and write it to a file
end
end
Here, we have a GENERATORS constant that maps the class to be called based on the employee type. We can use it to determine which class to call. Now, when we have to add new functionality, we can simply create a new class for that and add it in the GENERATORS constant. This helps to extend the class without breaking something or needing to think about the existing logic. We can easily add or remove any type of payslip generator.
Liskov Substitution Principle - LSP
The Liskov substitution principle states, "if S is a subtype of T, then objects of type T may be replaced with objects of type S".
To understand this principle, let us first understand the problem. Under the open/closed principle, we designed the software in such a way that it can be extended. We created a subclass Payslip generator that does a specific job. For the caller, the class that they are calling is unknown. These classes need to have the same behavior so that the caller is unable to tell the difference. By behavior, we mean that the methods in the class should be consistent. The methods in these classes should have the following characteristics:
- Have the same name
- Take the same number of arguments with the same data type
- Return the same data type
Let us look at the example of the payslip generator. We have two generators, one for full-time employees and the other for contractors. Now, to ensure that these payslips have consistent behavior, we need to inherit them from a base class. Let us define a base class called User.
class User
def generate
end
end
The subclass we created in the example of the open/close principle did not have a base class. We modify it to have the base class User:
class ContractorPayslipGenerator < User
def generate
# Code to generate payslip
end
end
class FullTimePayslipGenerator < User
def generate
# Code to generate payslip
end
end
Next, we define a set of methods that are required for any subclass that inherits the User class. We define these methods in the base class. In our case, we only need a single method, called generate.
class User
def generate
raise "NotImplemented"
end
end
Here, we have defined the generate method, which has a raise statement. So, any subclass that inherits the base class needs to have the generate method. If it is not present, this will raise an error that the method is not implemented. In this way, we can make sure that the subclass is consistent. With this, the caller can always be sure that the generate method is present.
This principle helps substitute any subclass easily without breaking things and without the need to make a lot of changes.
Interface Segregation Principle - ISP
The interface segregation principle is applicable to static languages, and since Ruby is a dynamic language, there is no concept of interfaces. Interfaces define the abstraction rules between classes.
The Principle states,
Clients should not be forced to depend upon interfaces that they don't use. - Robert C. Martin
What this means is that it is better to have many interfaces than a generalized interface that any class can use. If we define a generalized interface, the class has to depend on a definition that it does not use.
Ruby does not have interfaces, but let us look at the class and subclass concept to build something similar.
In the example used for the Liskov substitution principle, we saw that the subclass FullTimePayslipGenerator was inherited from the general class User. But User is a very generic class and could contain other methods. If we must have another functionality, such as Leave, it would have to be a subclass of User. Leave does not need to have a generate method, but it will be dependent on this method. So, instead of having a generic class, we can have a specific class for this:
class Generator
def generate
raise "NotImplemented"
end
end
class ContractorPayslipGenerator < Generator
def generate
# Code to generate payslip
end
end
class FullTimePayslipGenerator < Generator
def generate
# Code to generate payslip
end
end
This generator is specific to payslip generation, and the subclass does not need to depend on the generic User class.
Dependency Inversion Principle - DIP
Dependency inversion is a principle applied to decouple software modules.
A high-level module should not depend on a low-level module; both should depend on abstraction.
The design, using the above-described principles, guides us towards the dependency inversion principle. Any class that has a single responsibility needs things from other classes to work. To generate payroll, we need access to the database, and we need to write to a file once the report is generated. With the single responsibility principle, we are trying to have only one job for a single class. But, things like reading from the database and writing to a file need to be performed within the same class.
It is important to remove these dependencies and decouple the main business logic. This will help the code to be fluid during change, and change becomes predictable. The dependency needs to be inverted, and the caller of the module should have control over the dependency. In our payslip generator, the dependency is the source of data for the report; this code should be organized in such a way that the caller can specify the source. Control of the dependency needs to be inverted and can be easily modified by the caller.
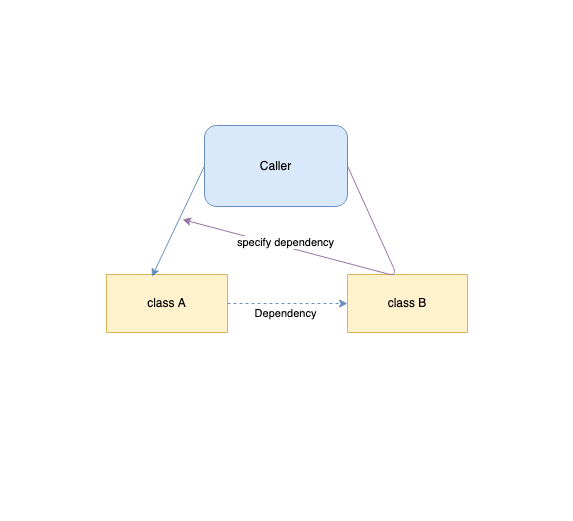
In our example above, the ContractorPayslipGenerator module controls the dependency, as determining where to read the data and how to store the output is controlled by the class. To revert this, let us create a UserReader class that reads the user data:
class UserReader
def get
raise "NotImplemented"
end
end
Now, let us suppose we want this to read data from Postgres. We create a subclass of the UserReader for this purpose:
class PostgresUserReader < UserReader
def get
# Code to read data from Postgres
end
end
Similarly, we can have a reader from FileUserReader, InMemoryUserReader, or any other type of reader we want. We now need to modify the FullTimePayslipGenerator class so that it uses PostgresUserReader as a dependency.
class FullTimePayslipGenerator < Generator
def initialize(datasource)
@datasource = datasource
end
def generate
# Code to generate payslip
data = datasource.get()
end
end
The caller can now pass the PostgresUserReader as a dependency:
datasource = PostgresUserReader.new()
FullTimePayslipGenerator.new(datasource)
The caller has control over the dependency and can easily change the source when needed.
Inverting the dependency does not only apply to classes. We also need to invert the configurations. For example, while connecting the Postgres server, we need specific configurations, such as DBURL, username, and passwords. Instead of hardcoding these configurations in the class, we need to pass them down from the caller.
class PostgresUserReader < UserReader
def initialize(config)
config = config
end
def get
# initialize DB with the config
self.config
# Code to read data from Postgres
end
end
Provide the config by the caller:
config = { url: "url", user: "user" }
datasource = PostgresUserReader.new(config)
FullTimePayslipGenerator.new(datasource)
The caller now has complete control over the dependency, and change management is easy and less painful.
Concluding
SOLID design helps to decouple the code and make change less painful. It is important to design programs in such a way that they are decoupled, reusable, and responsive to change. All of the five SOLID principles complement each other and should co-exist. A well-designed codebase is flexible, easy to change, and fun to work with. Any new developer can jump in and easily understand the code.
It is really important to understand what types of problems SOLID solves and why we are doing this. Understanding the problem helps you to embrace the design principles and design better software.

Written by
Milap NeupaneMilap is a Sr. Software engineer working with ruby/rails, Golang, and cloud-native technologies with AWS. He believes in the community and is the organizer of Golang Kathmandu. In his free time, Milap likes doing street photography.