Character Encoding for PHP Developers: Unicode, UTF-8 and ASCII
Your PHP project probably involves dealing with lots of data coming from different places, such as the database or an API, and every time you need to process it, you may run into an encoding issue.
This article will help you prepare for when that happens and better understand what's going on behind the scenes.
An introduction to encoding
Encoding is at the core of any programming language, and usually, we take it for granted. Everything works until it doesn't, and we get an ugly error, such as "Malformed UTF-8 characters, possibly incorrectly encoded".
To find out why something in the encoding might not work, we first need to understand what we mean by encoding and how it works.
Morse code
Morse code is a great way to explain what encoding is about. When it was developed, it was one of the first times in history that a message could be encoded, sent, and then decoded and understood by the receiver.
If we used Morse code to transmit a message, we'd first need to transform our message into dots and dashes (also called short and long marks), the only two signals available in this method. Once the message reaches its destination, the receiver needs to transform it from Morse code to English. It looks something like this:
"Hi" -> Encode("Hi") -> Send(".... ..") -> Decode(".... ..") -> "Hi"
This system was invented around 1837, and people manually encoded and decoded the messages. For example,
- S is encoded as ... (three short marks)
- T as - (one long mark)
- U as ..- (two short marks and one long mark)
Here's a radio operator encoding in Morse code:

On the Titanic, Morse code was used to send and receive messages, including the last one where they were asking for help ("CQD" is a distress call).
SOS SOS CQD CQD Titanic. We are sinking fast. Passengers are being put into boats. Titanic
In computer encoding, computers encode and decode characters in a very similar way. The only difference is that instead of dots and dashes, we have ones and zeros in a binary code.
Binary and characters
As you probably know, computers only understand binary code in 1s and 0s, so there's no such thing as a character. It's interpreted by the software you use.
To encode and decode characters into 1s and 0s, we need a standard way to do it so that if I send you a bunch of 1s and 0s, you will interpret them (decode them) in the same way I've encoded them.
Imagine what would happen if each computer translated binary code into characters and vice-versa in its own way. If you sent a message to a friend, they couldn't see your real message because, for their computer, your 1s and 0s would mean something else. This is why we need to agree on how we transform the characters into binary code and vice-versa; we need a standard.
Standards
Encoding standards have a long history. We don't need to fully explore the history here, but it's essential to know two significant milestones that defined how computers can use encoding, especially with the birth of the Internet.
ASCII
ASCII, developed in 1963, is one of the first and most important standards, and it is still in use (we'll explain this later). ASCII stands for American Standard Code for Information Interchange. The "American" part is very relevant since it could only encode 127 characters in its first version, including the English alphabet and some basic symbols, such as "?" and ";".
Here's the full table:

Computers can't really use numbers. As we already know, computers only understand binary code, 1s and 0s, so these values were then encoded into binary.
For example, "K" is 75 in ASCII, so we can transform it into binary by dividing 75 by 2 and continue until we get 0. If the division is not exact, we add 1 as a remainder:
75 / 2 = 37 + 1
37 / 2 = 18 + 1
18 / 2 = 9 + 0
9 / 2 = 4 + 1
4 / 2 = 2 + 0
2 / 2 = 1 + 0
1 / 2 = 0 + 1
Now, we extract the "remainders" and put in them in inverse order:
1101001 => 1001011
So, in ASCII, "K" is encoded as 1001011 in binary.
The main problem with ASCII was that it didn't cover other languages. If you wanted to use your computer in Russian or Japanese, you needed a different encoding standard, which would not be compatible with ASCII.
Have you ever seen symbols like "???" or "Ã,ÂÂÂÂ" in your text? They’re caused by an encoding problem. The program tries to interpret the characters using one encoding method, but they don't represent anything meaningful since it was created with another encoding method. This is why we needed our second big breakthrough, Unicode and UTF-8.
Unicode
The goal in developing Unicode was to have a unique way to transform any character or symbol in any language in the world into a unique number, nothing more.
If you go to unicode.org, you can look up the number for any character, including emojis!
For example, "A" is 65, "Y" is 121, and 🍐 is 127824.
The problem is that computers can only store and deal with binary code, so we still need to transform these numbers. A variety of encoding systems can achieve this feat, but we'll focus on the most common one today: UTF-8.
UTF-8
UTF-8 makes the Unicode standard usable by giving us an efficient way to transform numbers into binary code. In many cases, it's the default encoding for many programming languages and websites for two crucial reasons:
- UTF-8 (and Unicode) are compatible with ASCII. When UTF-8 was created in 1993, a lot of data was in ASCII, so by making UTF-8 compatible with it, people didn't need to transform the data before using it. Essentially, a file in ASCII can be treated as UTF-8, and it just works!
- UTF-8 is efficient. When we store or send characters through computers, it's important that they don't take up too much space. Who wants a 1 GB file when you can have a 256 MB one?
Let's explore how UTF-8 works a bit further and why it has different lengths depending on the character being encoded.
How is UTF-8 efficient?
UTF-8 stores the numbers in a dynamic way. The first ones in the Unicode list take 1 byte, but the last ones can take up to 4 bytes, so if you're dealing with an English file, most characters are likely only taking 1 byte, the same as in ASCII.
This works by covering different ranges in the Unicode spectrum with a different number of bytes.
For example, to encode any character in the original ASCII table (from 0 to 127 in decimals), we only need 7 bits since 2^7 = 128. Therefore, we can store everything in 1 byte of 8 bits, and we still have one free.
For the next range (from 128 to 2047), we need 11 bits since 2^11 = 2,048, which is 2 bytes in UTF-8, with some permanent bits to give us some clues. Let's take a look at the full table, and you'll see what I mean:
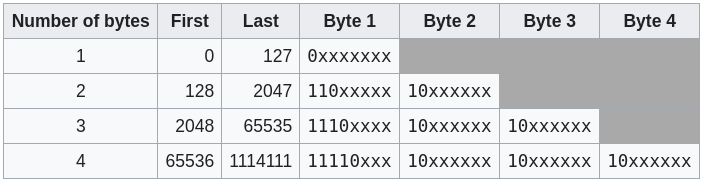
When reading 1s and 0s in a computer, we don't have the concept of space between them, so we need a way to say, "here comes this kind of value", or "read x bits now". In UTF-8, we achieve this by strategically placing some 1s and 0s.
If you're a computer and read something that starts with 0 in UTF-8, you know that you only need to read 1 byte and show the right character from Unicode in the range of 0-127.
If you encounter two 1s together, it means you need to read two bytes, and you're in the range of 128-2,047. Three 1s together means that you need to read three bytes.
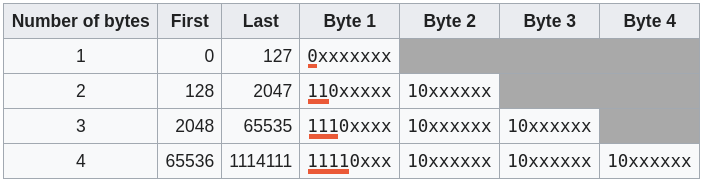
Let's see a couple of examples:
A character (such as "A") is translated into a number according to the giant Unicode table ("65"). Then, UTF-8 transforms this number into binary code (01000001) following the pattern we've shown.
If we have a character in a higher range, such as the emoji "⚡", which is 9889 according to Unicode, we need 3 bytes:
11100010 10011010 10100001
We can also show how this works with PHP just for fun:
// We first extract the hexadecimal value of a string, like "A"
$value = unpack('H*', "A");
// Convert it now from hexadecimal to decimal (just a number)
$unicodeValue = base_convert($value[1], 16, 10); // $unicodeValue is 65
// Now we transform it from base 10 (decimal) to base 2 (binary)
echo base_convert($unicodeValue, 10, 2); // 1000001
Encoding in PHP
Now that we've taken a look at how encoding works in general, we can focus on the essential parts that we usually need to handle in PHP.
A quick note on PHP versions
As you probably know, PHP has had a bad reputation for quite some time. However, thankfully, many of its original flaws were fixed in the more recent versions (from 5.X). Therefore, I recommend that you use the most modern version you can to prevent any unexpected problems.
Where encoding matters in PHP
There are usually three places where encoding matters in a program:
- The source code files for your program.
- The input you receive.
- The output you show or store in a database.
Setting the right default encoding
Since UTF-8 is so universal, it's a good idea to set it as the default encoding for PHP. This encoding is set by default, but if someone has changed this setting, here's how to do it. Go to your php.ini file and add (or update) the following line:
default_charset = "UTF-8"
What happens when a string coming in uses a different encoding? Let's see what to do in this case.
Detecting encoding
When we receive a string from reading a file, for example, or in a database, we don't know the encoding, so the first step is to detect it.
Detecting a specific encoding isn't always possible, but we have a good chance with mb_detect_encoding. To use it, we need to pass the string, a list of valid encodings that you expect to detect, and whether you want a strict comparison (recommended in most cases).
Here's an example of a way to determine whether a string is in UTF-8:
mb_detect_encoding($string, 'UTF-8', true);
With a list of potential encodings, we could pass a string or an array:
mb_detect_encoding($string, "JIS, eucjp-win, sjis-win", true);
$array[] = "ASCII";
$array[] = "JIS";
$array[] = "EUC-JP";
mb_detect_encoding($string, $array, true);
This function will return the detected character encoding or false if it cannot detect the encoding.
Convert to a different encoding
Once it's clear which encoding we're dealing with, the next step is transforming it to our default encoding, usually UTF-8. Now, this is not always possible since some encodings are not compatible, but we can try the following approach:
// Convert EUC-JP to UTF-8
$string = mb_convert_encoding($stringInEUCJP, "UTF-8", "EUC-JP");
If we want to auto-detect the encoding from a list, we can use the following:
// Auto detect encoding from JIS, eucjp-win, sjis-win, then convert str to UTF-8
$string = mb_convert_encoding($str, "UTF-8", "JIS, eucjp-win, sjis-win");
We also have another function in PHP called iconv, but since it depends on the underlying implementation, using mb_convert_encoding is more reliable and consistent.
Checking that we have the right encoding
Before processing or storing any input, it is a good idea to check that we have the string in the right encoding. To achieve this, we can use mb_check_encoding, and it'll return true or false. For example, to check that a string is in UTF-8:
mb_check_encoding($string, "UTF-8");
Output in HTML
Since it's so common to render some HTML code for a website from PHP, here's how we can make sure that we set the right encoding for the browser. We can do it just by sending a header before the output:
header('Content-Type: text/html; charset=utf-8');
A note on databases
Databases are an important part of handling encoding correctly since they are configured to use one for all the data we have there.
In many cases, they're where we'll store all our strings and from where we'll read them to show them to the user.
I recommend that you make sure that the encoding you're using for your project is also the same you have set in your database to prevent problems in the future.
Setting your encoding for the database depends on the database system you use, so we can't describe every way in this article. However, it makes sense to go to the online docs and see how we can change it. For example, here's how to do it with PostgreSQL and with MySQL.
Common encoding-related errors in PHP
Malformed UTF-8 characters, possibly incorrectly encoded
When transforming an array to JSON with json_encode, you might run into this issue. This just means that what PHP was expecting to get as UTF-8 is not in that encoding, so we can solve the problem by converting it first:
$array['name'] = mb_convert_encoding($array['name'], 'UTF-8', 'UTF-8');
Encoding error in the database
When reading from or writing to a database, you might run into some weird characters, such as the following:
T�léawe
This error is usually a sign that the encoding you're using to read your string is not the same one that the database is using. To fix this issue, make sure that you're checking the string's encoding before storing it and that you have set the right encoding in your database.
Conclusion
Encoding is sometimes difficult to understand, but hopefully, with this article, it's a bit clearer, and you feel more prepared to fix any errors that might come your way.
The most important lesson to take away is to always remember that all strings have an associated encoding, so make sure you're using the right one from the first time you encounter it, and use the same encoding in your whole project, including the database and source files. If you need to pick one, pick a modern and common one, such as UTF-8, since it will serve you well with any new characters that might appear in the future, and it's very well designed.

Written by
José M. GilgadoJosé is a senior software engineer with over 10 years of experience. He works remotely at Buffer from Spain and loves good books and coffee.