The string is arguably the most essential data type in programming; every programming language and software in the world uses strings in one way or another. It enables humans to easily communicate with sophisticated programs and machines. One thing that would help you a lot as a programmer is understanding how to use and manipulate strings so that you can build programs users can utilize efficiently.
Regular expressions enable developers to perform a wide range of text processing tasks, such as data validation, string manipulation, and text extraction, in a very concise way. In this article, you will learn everything you need to know about regular expressions, and you can start using them efficiently in your JavaScript code.
Prerequisites
To get the most out of this tutorial, you only need a basic understanding of JavaScript; all the concepts and code samples will be explained in detail.
Now that you know the prerequisites, let’s look at what regular expressions are in the next section.
Regular expressions in JavaScript
Regular expressions, also known as regex or regexp, are a pattern or template for matching strings. These patterns are a sequence of characters that define a search pattern, allowing developers to perform tasks, such as validating input data, searching for specific text, and replacing parts of a string.
Let's look at an example of how regular expressions can help you with these tasks by exploring an example of extracting email addresses from text:
let text = "John's email is john@example.com and Jane's email is jane@example.com. You can contact them at these addresses.";
let words = text.split(" ");
let emails = [];
for (let i = 0; i < words.length; i++) {
if (words[i].includes("@")) {
emails.push(words[i]);
}
}
console.log(emails);
The code above uses a for loop with an if statement to extract the words with an @ symbol into an array called emails.
Let's see how regular expressions can solve this problem:
let text = "John's email is john@example.com and Jane's email is jane@example.com. You can contact them at these addresses.";
let emails = text.match(/\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}\b/g);
console.log(emails);
The code above solves the same problem but with a regex approach and fewer lines of code. Both solutions should return the same result:

Don't worry if you don't understand the regex pattern; you will be ready to start creating your patterns by the end of this tutorial.
In the next section, let's look at how to create regular expression patterns in JavaScript.
Creating regular expression patterns in JavaScript
There are two ways to create regular expression patterns in JavaScript. We’ll discuss them in this section.
Using literal notation
The simplest way to create a regular expression pattern in JavaScript is to use literal notation. You can create a pattern by simply enclosing it in forward slashes:
let pattern = /Hello/;
The code above creates a simple regex pattern that will match the first occurrence of the exact text "Hello". This notation is used when you know how the pattern will look when writing the code.
Note: You don't need to enclose the patterns in single or double quotes; you can add flags after the closing forward slash.
Using constructor notation
JavaScript has a RegExp constructor that you can use to create regex patterns. You pass the pattern as a string argument to the constructor:
let pattern = new RegExp("\\w+", "g");
The code above creates a pattern that matches all the words in a given text. The first string argument is the pattern, and the second is the flag. You'll learn more about flags in the following sections.
The constructor notation is used when you want to dynamically generate regular expressions. For example, if you want to build a Find and Replace function inside your application, you will want to allow the user to add the text they want to match instead of hardcoding it. You can create a dynamic pattern:
function find(regexInput, text) {
const regexPattern = new RegExp(`${regexInput}`, "gi");
console.log(regexPattern.exec(text))
}
find("lazy", "The quick brown fox jumps over the lazy dog.") // returns "lazy"
The code above creates a find function that takes regexInput and text. It then creates a regexPattern that creates a pattern based on the regexInput; finally, it logs the matched text in the console using the exec method on the generated pattern.
Note: You don't need to add forward slashes to the pattern when using the
RegExpconstructor to create patterns, but you do need to enclose them in either single or double quotes.
Testing regular expression patterns in JavaScript
There are different ways to test regex patterns in JavaScript, depending on how you want the result returned.
The match method
The match method returns an array with the matched string and null if there is no match. You can use the match method with the pattern as the parameter on the given input:
let pattern = /Hello/;
let input = "Hello, World!";
let result = input.match(pattern);
console.log(result);
The code above creates a pattern that will match the first occurrence of the text "Hello", a variable named input, and a result variable that will be logged to the console. The result should look like this:

The image above shows the test result: an array containing the text that matched, the index of the first letter, the given input, and the groups, which are undefined in this case.
The test method
The test method searches a string for a regular expression pattern and returns true if it finds a match and false if it doesn't. Here is an example:
let pattern = new RegExp("peaky", "gi");
let input = "Peaky Blinder is an interesting series";
let result = pattern.test(input);
console.log(result); // returns true
The code above creates a pattern to match the word "Peaky", provides an input variable, uses the test method to check if there is a match, and then logs the result to the console.
The exec method
The exec method searches a string for a regular expression pattern and returns an array containing the matched substrings. Unlike the match method, the exec method returns multiple arrays for multiple matches.
For example, you can test a pattern using the exec method:
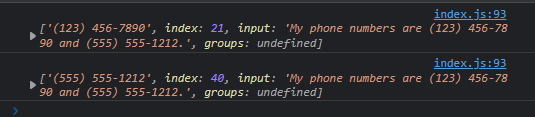
const pattern = /\(\d{3}\) \d{3}-\d{4}/g;
const string = "My phone numbers are (123) 456-7890 and (555) 555-1212.";
let matches;
while (matches = pattern.exec(string)) {
console.log(matches);
}
The code above creates a pattern that matches phone numbers, a string that includes two phone numbers in the format specified by the pattern, and a while loop that iterates over all matches found by the exec method and logs each match to the console. The code above will return the following:
The search method
The search method typically works on all strings, but you can also use it to test regex patterns:
let text = "Hello, welcome to the world of hello!";
let pattern = /hello/i;
let index = text.search(pattern);
console.log(index); // returns 0
The code above creates a pattern that matches the word "Hello" and uses the i flag to perform a case-insensitive search; it then uses the search method to return the index of the first match within the text string.
Now that you know what regular expressions are and how they help you as a developer, let's explore the syntax and structure of regular expressions in the next section.
Syntax and structure of regular expressions
As mentioned above, regular expression patterns primarily consist of literal and special characters.
Literal characters
This is the most basic form of a regular expression; it can consist of one or more literal characters and matches itself precisely in a string. When using only literal characters, the pattern a matches the string a, and the pattern big matches the string big. It only matches the first occurrence of the given character or set of characters in the given string.
For example, if given a string of "Ben has grown bigger since I saw him last. Sally and Mary are big girls now too", the pattern big will match only the first big in the string, and it does not matter that it is part of a single word. Also, the other big in the string does not matter because I only used literal characters.
Note: Regular expressions are case-sensitive by default, and
bigis not the same asBigunless you use special characters to ignore the case difference.
In the next section, let's see how to match standalone words and more than one occurrence with special characters.
Special characters
In most cases, you would want to match more than just literal characters. Regular expressions also include a set of special characters known as metacharacters. These characters have special meanings and are used to match a set of characters rather than matching themselves.
These special characters can be combined to form complex patterns that match a wide range of strings. I will go through the common special characters and their related concept in the following sections.
Now that you know what literal and special characters are, let's look at some common flags in regular expressions.
Flags
Flags are used to modify the behavior of pattern matching in regular expressions. They can change how a pattern is applied and affect the matching process in different ways.
Some of the most common flags include the following:
The g flag
The g flag is used to perform global pattern matching. When this flag is set, the regular expression engine will search for matches even after the first match is found. Without this flag, the regular expression engine will only find the first match in the input string.
For example, the regular expression /hello/g will match all occurrences of the string "hello" in the input string. Without the g flag, the regular expression engine would only match the first occurrence.
The i flag
The i flag is used to perform case-insensitive pattern matching. The regular expression engine will match uppercase and lowercase characters when this flag is set. Without this flag, the regular expression engine will only match characters with the same case as the pattern.
For example, the regular expression /hello/gi will match both "hello" and "Hello" in the input string.
The m flag
The m flag is used to perform multi-line pattern matching. When this flag is set, the regular expression engine will treat the input string as a multi-line string and match patterns across multiple lines.
For example, the regular expression /^hello/gm will match all occurrences of the string "hello" at the beginning of a line in a multi-line input string.
The s flag
The s flag is used to perform single-line pattern matching. When this flag is set, the regular expression engine will treat the input string as a single-line string and match patterns across the entire string, including newline characters.
For example, the regular expression /hello.world/s will match the string "hello\nworld" in the input string.
The u flag
The u flag is used to perform Unicode pattern matching. When this flag is set, the regular expression engine will use Unicode character properties and case mapping to match characters.
For example, the regular expression /[^\p{L}\p{N}]+/u will match any sequence of characters that are not letters or numbers in a Unicode string.
Now that you know the common flags in regular expressions, let's discuss regular expression concepts and their corresponding metacharacters in the next section.
Regular expression concepts and metacharacters
There are different regular expression concepts that you can use to create patterns in your code. I'll describe and explain the common ones with their related concept in this section.
Character classes
Also known as character sets, character classes are used to tell the regex engine to match certain characters in a given string. A good example is when you are unsure whether the text you're checking uses American or British English.
For example, the words apologize and apologise are both correct depending on which country's English the given text is written in, so to match one or both in a text, you can use a character class with square brackets:
let pattern = new RegExp('apologi[sz]e', 'g');
let input = "apologize and apologise are both correct";
let result = input.match(pattern);
console.log(result); // returns ['apologize', 'apologise']
The code above creates a pattern that will match both American and British spelling of the word apologize, tests it, and then logs the matched words to the console.
Character sets also work very well when trying to validate commonly misspelled words, such as calendar and cemetery:
let pattern = new RegExp('calend[ea]r', 'g');
let input = "calendar or calender";
let result = input.match(pattern);
console.log(result); // returns ['calender', 'calendar']
The code above does the same thing as the previous code block but with a commonly misspelled word, "Calender".
Negated character set
A negated character class does the opposite of what a character class does. You can negate a character class by adding a caret ^ after the opening square brackets:
let pattern = new RegExp('[^vwy]et', 'g');
let input = "get, yet, bet, wet, let, vet";
let result = input.match(pattern);
console.log(result); returns ['get', 'bet', 'let']
The code above will match all the words that end with "et" except the ones that start "v", "w", or "y".
Ranges
A range is a shorter way to write a character set. For example, if you want to match all figures that start with any number between 2 and 6 and end with double zeroes, you can do this with a range:
let pattern = new RegExp('[2-6]00', 'g');
let input = "200, 700, 300, 100, 590, 400";
let result = input.match(pattern);
console.log(result); // returns ['200', '300', '400']
The code above uses the hyphen - to define a range, tests it, and then logs the result to a console. You can do the same thing for words:
let pattern = new RegExp('[a-h]010290', 'g');
let input = "a010290, i010290, d010290, f010290, i010290, n010290, s010290";
let result = input.match(pattern);
console.log(result); // returns ['a010290', 'd010290', 'f010290']
The code above does the same thing as the previous one, but this time, with words that start with letters a-h and ends with 010290.
There's another way to write ranges, which is to use the short codes for [a-z, [0-9] and their exact opposites. For example, you can write a function that extracts email addresses from text:
const pattern = /\w+@\w+\.\w+/g;
const text = "John's email is john@example.com and Jane's email is jane@example.com. You can contact them at these addresses.";
console.log(text.match(pattern)); // returns ['john@example.com', 'jane@example.com']
The code above creates a pattern that matches emails in a text using the \w, which is a shortcode for [A-Za-z0-9_].
Let's look at more of these shortcodes and their descriptions:
- \d - Matches any digit.
- \w - Matches any word character, which includes any alphanumeric character and underscore (_).
- \s - Matches any whitespace character, including spaces, tabs, and line breaks.
- \D - Opposite of
\d; matches any character that is not a digit. - \W - Opposite of
\w; matches any character that is not a word character. - \S - Opposite of
\s; matches any character that is not a whitespace character.
You can combine one or more metacharacters to quickly create complex patterns. For example, the pattern \d{3}-\d{2}-\d{4} could be used to match a United States Social Security number in the format "323-45-6789".
Let's explore quantifiers and how they work in the next section.
Quantifiers
Quantifiers specify how many times a particular character or group of characters should appear in a given string. They are used to define the quantity or range of characters that a regular expression should match. The following paragraphs explain some special characters that represent quantifiers.
Asterisk (*)
The asterisk (*) is one of the most common quantifiers, representing zero or more occurrences of the preceding character or group. For example, the regular expression "a" will match any string that contains zero or more "a" characters. This means that it will match an empty string and any string that consists entirely of "a" characters:
const pattern = /a*/;
const text = "Our organisation is committed to providing excellent customer service and fostering strong relationships with our clients.";
console.log(text.match(pattern)); returns ['']
Plus (+)
Another common quantifier is the plus sign (+), which represents one or more occurrences of the preceding character or group. For example, the regular expression "a+" will match any string that contains one or more "a" characters. This means that it will not match an empty string but will match any string that consists entirely of "a" characters or contains at least one "a":
const pattern = /a+/g;
const text = "Our organisation is committed to providing excellent customer service and fostering strong relationships with our clients.";
console.log(text.match(pattern)); // returns ['a', 'a', 'a', 'a']
The code above will match and return all the occurrences of the character "a" in the given string.
Curly braces ({})
The curly braces ({}) quantifier specifies an exact number of occurrences of a character or group. For example, the regular expression /a{2,4}/ will match any string between two and four "a" characters. This means that it will match strings like "aa", "aaa", or "aaaa", but not strings with fewer than two "a" characters or more than four:
const pattern = /a{2,4}/g;
const text = "Our orgaanisation is committed to providing excellent customer service aaand fostering strong relaaaationships with our clients.";
console.log(text.match(pattern)); // returns ['aa', 'aaa', 'aaaa']
Lazy quantifiers
As seen in the previous section, quantifiers are used in regular expressions to match multiple pattern occurrences. For example, the + quantifier matches one or more occurrences of a pattern, and the * quantifier matches zero or more occurrences of a pattern. The ? quantifier matches zero or one occurrence of a pattern.
By default, quantifiers are greedy, meaning they match as much of the string as possible. You can make quantifiers lazy by appending a ? to the quantifier. Lazy quantifiers can be helpful when you want to match a pattern that occurs multiple times in a string, but you only want to match the first occurrence. For example, consider the following regular expression:
const string = 'the cat sat on the mat';
const regex = /the.+?on/;
const match = string.match(regex);
console.log(match); // returns ['the cat sat on']
The code above creates a pattern that matches only the string from "the" to "on", excluding "mat" because the .+? quantifier is lazy and matches as little of the string as possible.
Now that you know how to use quantifiers in regular expressions, let's explore repetition in the next section.
Repetition
Another important feature of regular expressions is repetition. Repetition is matching patterns that occur multiple times within a string. This is often achieved using quantifiers, but there are other ways to achieve repetition.
Parentheses (())
You can achieve repetition by using parentheses to group a pattern and then applying a quantifier to that group. For example, the pattern (ab)+ will match any string that contains one or more occurrences of the pattern "ab":
const pattern = /(ab)+/g;
const text = "abb abcb ababab";
console.log(text.match(pattern)); // returns ['ab', 'ab', 'ababab']
Dot (.)
Another way to achieve repetition is by using the dot (.) metacharacter. For example, the dot character represents any single character, and the question mark (?) character represents zero or one occurrence of the preceding character or group. These characters can be combined with quantifiers to match patterns that repeat in specific ways.
For example, the pattern a.{?}b will match any string that starts with an "a", followed by between three and five of any character, and ends with a "b":
const pattern = /a.{3,5}b/g;
const text = "abbabcb desbdd cescse ababab";
console.log(text.match(pattern)); // returns ['abbabcb', 'ababab']
Pipe (|)
Another metacharacter often used for repetition is the pipe character (|), which represents a choice between two patterns. For example, the pattern a(b|c)d will match any string that starts with an "a", followed by either a "b" or a "c", and ends with a "d":
const pattern = /a(b|c)d/g;
const text = "abcd dde acd abd";
console.log(text.match(pattern)); // returns ['acd', 'abd']
Let's look at how to escape metacharacters in the next section.
Escaping
One of the most important concepts you need to understand to avoid errors when using regular expressions is how to escape special characters with a backslash \ in front of them. For example, to match words that ends with a + sign, you need to escape the \+ special character:
let pattern = new RegExp('\\w+\\+', 'g');
let input = "wee+, let, kit, iPhone8+, i010290, n010290, s010290";
let result = input.match(pattern);
console.log(result); // returns ['wee+', 'iPhone8+']
The code above creates a pattern that matches words that end with a + sign by escaping the \+ special character. Without the extra \ before the special characters, the regex engine will read the pattern as /w++/, which is invalid.
Note: When using a literal notation, you can define the pattern like
let pattern = /\w+\+/g, and the code above should work fine.
Anchors
You can use anchors to match the start or end of a line or word in a string. The commonly used anchors are ^, which matches the beginning of a line, and $, which matches the end of a line.
For example, you can match the word "The" that is at the start of the string:
const pattern = /^The/;
const string = "The quick brown fox jumps over the lazy dog.";
console.log(string.match(pattern)); // Output: ["The"]
You can do the opposite with the $ sign:
const pattern = /\.$/;
const string = "The quick brown fox jumps over the lazy dog.";
console.log(string.match(pattern)); // Output: ["."]
The code above creates a pattern that matches the character "." at the end of the given string.
Word boundaries
Word boundaries serve the same purpose as anchors but match a word instead of a single character. These are the two-word boundaries for special characters:
\b- Matches a word boundary, which is the position between a word character and a non-word character.\B- Opposite of\b; matches a non-word boundary.
For example, you can match all words that start with "bet":
const pattern = /\bbet/gi;
const text = "Betty's better bet was to buy the blue blouse.";
console.log(text.match(pattern)); // returns ['Bet', 'bet', 'bet']
The code above creates a pattern that returns the number of times the letters "bet" begin a word in the given sentence, regardless of the case.
Furthermore, just like anchors, you can do the opposite by adding the \b at the end of the word:
const pattern = /sion\b/gi;
const text = "After much discussion, the team came to a consensus on the vision for the project.";
console.log(text.match(pattern)); // returns ['sion', 'sion']
The code above creates a pattern that returns the number of times that words in the given sentence end with the letter "sion", regardless of the case.
Alternatives
Sometimes, you need to validate a string where only one of the multiple words is allowed. For example, you might want to match either business or organization in a given string:
const pattern = /business|organisation/gi;
const text = "Our organisation is committed to providing excellent customer service and fostering strong relationships with our clients.";
console.log(text.match(pattern)); // returns ['organisation']
The code above will return ['organization'] or ['business'] depending on the one that is included in the given string.
Grouping
Grouping is used when you want to use alternatives multiple times in your pattern. For example:
const pattern = /(quick|lazy) (brown|gray) (fox|dog)/;
const text = "The quick brown fox jumps over the lazy dog.";
console.log(text.match(pattern)); // returns ["quick brown fox"]
The code above creates a pattern that matches the phrase "quick brown fox" or "lazy gray dog" in the given string.
Capturing groups
Capturing groups are used to group and capture parts of a pattern in a regular expression. Capturing groups are enclosed within parentheses, instructing the regular expression engine to remember the matched content within the group.
For example, the following pattern, (hello)+, will match any sequence of the word "hello" one or more times. However, if you wrap the "hello" sequence within a capturing group, ((hello)+), you can capture the matched content within the group. The regular expression engine will match and capture the entire sequence, including repeated occurrences of the word "hello".
Let's look at a good use case for capturing groups:
const date = '02/18/2023';
const regex = /(\d{2})\/(\d{2})\/(\d{4})/;
const newDate = date.replace(regex, '$3-$1-$2');
console.log(newDate); // returns '2023-02-18'
The code above uses capturing groups to create a pattern that captures the string's month, day, and year parts within separate groups. It then uses backreferences to reference the captured groups in the replacement string in the format $n, where n is the group number. Finally, it references the third, first, and second groups using $3, $1, and $2 to rearrange the date in the desired format.
Let's explore backreferences in the next section.
Backreferences
Backreferences are a powerful feature of regular expressions that allow you to reference captured groups within a regular expression. As the previous example shows, I used the $n notation to reference a captured group, where n is the group number.
Backreferences are commonly used to find and replace duplicate words within a string. For example, you can use a regular expression with a capturing group and a backreference to find and replace duplicate words:
const string = 'the the cat sat on the mat';
const regex = /\b(\w+)\b\s+\1/g;
const newString = string.replace(regex, '$1');
console.log(newString); // Output: 'the cat sat on mat.'
The code above creates a pattern that matches any duplicate word within the string. The pattern uses a word boundary \b to ensure that it matches only complete words, a capturing group (\w+) to capture the word, and a backreference \1 to reference the captured word. Then, it uses the replace method to replace the entire match with the captured word, effectively removing the duplicate word.
Let's take a look at named capturing groups in the next section.
Named capturing groups
Named capturing groups are a variation of capturing groups that allow you to assign names to the captured groups, making it easier to extract the matched text. Named capturing groups are represented by the (?<name>...) syntax, where name is the name of the capturing group. Here is an example:
const string = 'John Doe';
const regex = /(?<first>\w+)\s(?<last>\w+)/;
const match = string.match(regex);
console.log(match.groups); // returns { first: 'John', last: 'Doe' }
The code above creates a pattern that matches two words separated by a space and creates two named capturing groups, first for the first word and last for the second word, and then logs the group properties to the console using the groups method.
Named capturing groups can be helpful when you want to extract specific parts of a string using regular expressions. For example, you can use named capturing groups to extract data from a structured text file, such as a log file or a configuration file.
Let's explore the lookahead and lookbehind assertions in the next section.
Lookaheads and lookbehinds
Lookaheads and lookbehinds are powerful features of regular expressions that allow you to match patterns based on what comes before or after a given pattern without including the lookbehind or lookahead in the match. These constructs are represented by the (?<=...) and (?<!...) lookbehind assertions, as well as the (?=...) and (?!...) lookahead assertions.
A lookahead assertion matches a pattern only if another pattern follows it. For example, suppose you want to match any word followed by "is". You can use a positive lookahead assertion to match any word that is immediately followed by the word "is":
const string = 'The sky is blue';
const regex = /\w+(?=\sis)/g;
const matches = string.match(regex);
console.log(matches); // returns ['sky']
The code above creates a pattern that matches any word immediately followed by the word "is" but does not include the word "is" in the match.
A lookbehind assertion matches a pattern only if another pattern precedes it. For example, if you want to match any word preceded by the word "the", you can use a positive lookbehind assertion to match any word that immediately follows the word "the":
const string = 'The cat sat on the mat';
const regex = /(?<=the\s)\w+/gi;
const matches = string.match(regex);
console.log(matches); // returns ['cat', 'mat']
The code above creates a pattern that matches any word immediately follows the word "is" but does not include the word "is" in the match.
Lookaheads and lookbehinds can be combined with other regular expression constructs, such as quantifiers, character classes, and alternation, to match more complex patterns.
Matching Unicode in regular expressions
Unicode is a character encoding standard that allows you to represent characters from different languages and scripts. Regular expressions provide a /u flag to match a Unicode character in hexadecimal format.
You can use Unicode characters in character classes, quantifiers, and other regular expression constructs. However, matching Unicode characters can be tricky, as multiple code points represent some Unicode characters. For example, the character "é" can be represented by either the code point \u00e9 or by combining the code points \u0065 and \u0301. This can lead to unexpected results when matching Unicode characters in regular expressions.
To handle this, you can use the u flag, which enables Unicode mode in regular expressions. In Unicode mode, regular expressions know code point sequences and can match Unicode characters correctly. For example, consider the following regular expression:
const string = 'café';
const regex = /f\u00e9/u;
const match = string.match(regex);
console.log(match); // returns ['fé']
The code above creates a pattern that matches the character "é" in Unicode format by using the/u flag to enable Unicode mode in the regular expression.
Let's explore some real world use cases of regular expression in the next section.
Common real-world use cases
In this section, I will show you some real-world use cases for regular expressions in JavaScript.
Form validation
Regular expressions can be used to validate form data, such as email addresses, phone numbers, and passwords. Here's an example of using regular expressions to validate an email address:
function validateEmail(email) {
const emailPattern = /^[^\s@]+@[^\s@]+\.[^\s@]+$/;
return emailPattern.test(email);
}
console.log(validateEmail('user@example.com')); // true
console.log(validateEmail('invalid_email')); // false
Search and replace
Regular expressions can be used to search and replace text in a string. For example, you could use a regular expression to replace all instances of a word in a paragraph with another word:
const paragraph = 'The quick brown fox jumps over the lazy dog';
const newParagraph = paragraph.replace(/quick/g, 'slow');
console.log(newParagraph); // returns 'The slow brown fox jumps over the lazy dog'
Parsing data
Regular expressions can be used to extract specific data from a string. For example, you could use a regular expression to extract all the URLs from a block of text:
const text = 'Check out this site: https://www.example.com and also this one: https://www.another-example.com';
const urls = text.match(/https?:\/\/\S+/g);
console.log(urls); // returns ['https://www.example.com', 'https://www.another-example.com']
String manipulation
Regular expressions can be used to manipulate strings in various ways. For example, you could use a regular expression to remove all non-alphanumeric characters from a string:
const string = 'Th1s !s 4n ex@mpl3.';
const newString = string.replace(/[^a-zA-Z0-9]/g, '');
console.log(newString); // returns 'Th1s4nexmpl3'
URL routing
Regular expressions can be used to match and extract parameters from URLs in a web application. For example, you could use a regular expression to match and extract the ID parameter from a URL:
const url = '/users/123';
const id = url.match(/\/users\/(\d+)/)[1];
console.log(id); // returns '123'
These are just a few examples of the many ways regular expressions can be used in JavaScript.
Conclusion
Regular expressions are a powerful tool for working with text in JavaScript. With the ability to match, search, and replace text using complex patterns, regular expressions are essential for any developer. You’ve learned the basics of regular expressions, including syntax, character sets, and repetition, as well as advanced topics such as lookaheads, lazy quantifiers, and Unicode support.
Additionally, you’ve explored real-world use cases for regular expressions, including form validation, data parsing, search and replace, and URL routing. With the knowledge of regular expressions, you can improve the efficiency and accuracy of your text-processing tasks in JavaScript.
That was a long one! Thank you so much for reading, and I hope this article achieved its aim of teaching you everything you need to know to start using regular expressions effectively in your code.


