Software developers need a way to make applications communicate with each other and share necessary data, which is where APIs come into play. An application programming interface (API) is an interface for building and integrating applications.
Currently, the most common way to create an API is by using REST, so when you're creating an API that uses this architecture, you can say that you are building a RESTful API, but what does it mean? What is REST?
REST
Representational state transfer (REST) is an architectural style for standardizing applications to facilitate communication between them. Thus, a RESTful API is just an API based on REST that uses HTTP requests, such as GET, POST, PUT, PATCH, or DELETE, to access and use the data of a resource.
The requests and responses of an API consist of three parts: the status code, headers, and the body. For example, if you search for something using Google, go to the network tab and click on the first element, you will see the headers subtab, which looks something like this:
Request Method: GET
Status Code: 200
...
The response body is the HTML that you see on the browser; you can see it on the response subtab.
Headers allow us to specify some options, including the content type of the endpoint, such as JSON or XML, and authorization tokens. The status code indicates the result status of a request. If you attempt to load a page that doesn't exist, you often see a 404 page, which is a status code. The Google example above returned a 200 status, which means the request was successful.
Resources are an essential component of REST; they are an abstraction of your application domains, just like OOP. For example, you can have a resource called users and access it through a URL by performing some actions called resource methods; however, these methods are different from the HTTP methods.
Thus, your RESTful API for users may look like this:
- GET /users -> Fetch all Users
- GET /users/:id -> Fetch a specific User by its ID
- POST /users -> Create a new User
- PUT /users/:id -> Update a User
- DELETE /users/:id -> Delete a User
Like any other architecture, REST has constraints:
- Uniform Interface: This means that if a developer becomes familiar with one endpoint, he or she should be able to become familiar with the others.
- Client-server: Both sides are independent but must use the same interface to communicate.
- Stateless: The client is responsible for managing the state of the application, not the server.
- Cacheable: Caching can help improve performance.
Advantages
- Scalability: The product can scale quickly since the client and server are separate; you can run them on separate servers by different teams.
- Flexibility: REST APIs accept diverse data formats, such as JSON and XML, so you can change them and experiment without much effort.
- Independence: Stateless communication helps to make the API less complex by focusing on their concerns.
Disadvantages
- Over-fetching: Sometimes, you need less data than the endpoint gives you, but there is no way to inform the REST API, and retrieving all the data can be expensive in many ways.
- Under-fetching: In the opposite scenario, you sometimes need more data than the endpoint gives you, so it is necessary to make more requests.
- Versioning: If you want to avoid breaking changes to your clients, it's essential to create an API version, but it's difficult to maintain.
REST is an option, but a recent alternative called GraphQL allows us to construct flexible APIs.
GraphQL
GraphQL was created by Facebook to build APIs. They define it as a Query Language for APIs and a runtime for fulfilling queries with your existing data. Most importantly, it gives clients the power to ask for exactly what they need.
A GraphQL query is very descriptive; you specify which fields you from of a resource, and you only get what you asked for. For example, this is a query where you want the first name, last name, and the email of a user:
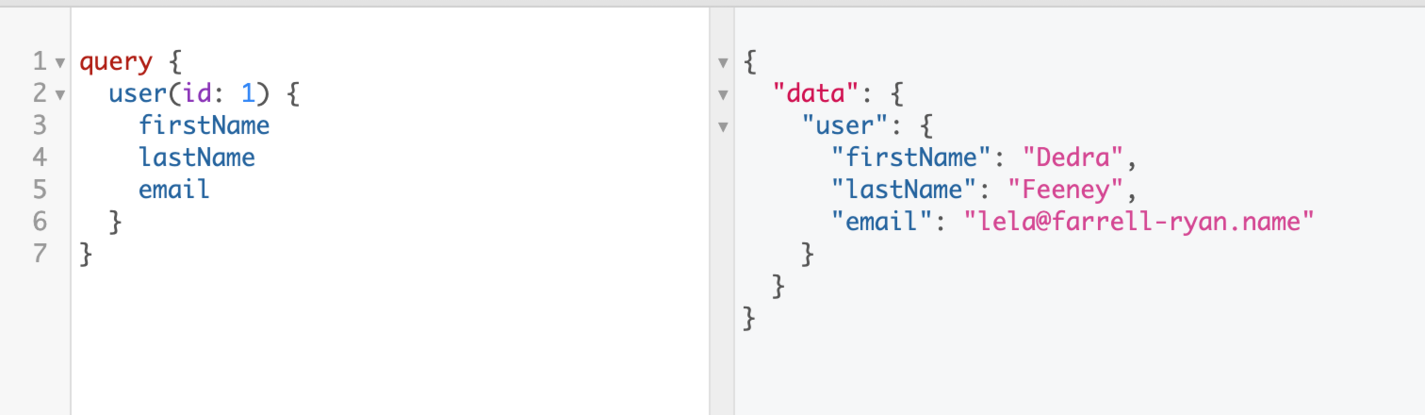
The main difference between GraphQL and REST is that GraphQL is a language and a technology, while REST is an architecture pattern. In most cases, GraphQL is used for teams whose data retrieval needs are not met by traditional REST APIs.
We need to understand some concepts before continuing, and they are essential to understanding how GraphQL works. The first one is schema; it is the core concept, and it defines the functionality available to the client applications.
GraphQL is a strongly typed language, so it has a type system that helps us define a contract between the client and server; these are some of its types:
- Scalar types (Int, Float, String, Boolean, and ID)
- Object
- Query (Used to fetch data, basically your GET requests)
- Mutation (Used to modify, create, and delete data, basically your POST, PUT, and DELETE requests)
Advantages
- No Over and Under fetching: You ask for the data you need.
- Single Source Truth: You only have an endpoint, so there’s no need to call many endpoints for each resource.
- Strong Typing: You need to define the type of each resource attribute; it reduces errors significantly, and it's easier to debug if the endpoint fails.
- No Versioning: GraphQL deprecates APIs on a field level; you can remove aging fields from the schema without impacting the existing queries.
Disadvantages
- Data Caching: The cache in GraphQL is performed on the client-side, but doing so requires adding a lot of extra data or use some external libraries.
- Complexity: The learning curve is more extended than REST because you need to learn a language, types, and how to make requests.
- Performance issues: Sometimes, you can abuse nested attributes on requests, and if your server is not prepared for it, you could encounter N+1 problems.
- File uploading: GraphQL doesn't support this out of the box, so if you want to use images, you will have to use Base64 encoding or a library like Apollo.
- Status Code 200 for everything: You only get a Status 200 (Ok) for all your requests, even if they fail; this is not helpful for the developer experience.
Now that you know a few things about GraphQL, let's code to understand more about it!
Creating a GraphQL API with Ruby on Rails
Setting Up
First, create a Rails API project by running the following command:
> rails new graphql_example --api
For this example, we'll create an application in which a user can create movies in a helpful but straightforward manner. Let's make our models:
> rails g model User email first_name last_name
> rails g model Movie user:references title year:integer genre
Don't forget to run the migrations:
> rails db:migrate
Open your user model and add the relationship to the movie model by using something like this:
# app/models/user.rb
class User < ApplicationRecord
has_many :movies, dependent: :destroy
end
Installing GraphQL
The next step is to add the GraphQL gem to our Gemfile; you can visit its page, graphql-ruby, for more details; now, open your Gemfile and add this line:
# Gemfile
gem 'graphql'
group :development do
gem 'graphiql-rails'
end
As you can see, we are adding two gems. The first one is the GraphQL implementation, and the second one is the graphic interface (graphiql) to test our endpoints in the development environment. That's so cool!
Install these gems by running the following in the console:
> bundle install
Finally, set up the necessary for graphql by executing the following instruction:
> rails generate graphql:install
After the installation, you'll see the message "Skipped graphiql, as this rails project is API only" in the console because we created the project with the API flag. However, if you have a full Rails project, is not necessary to add the graphiql-rails gem, as the previous command will do it for you.
We now have GraphQL in our project; you can see we have a folder called graphql within the app and a graphql controller:
> tree app/graphql
app/graphql
├── graphql_example_schema.rb
├── mutations
│ ├── base_mutation.rb
└── types
├── base_argument.rb
├── base_enum.rb
├── base_field.rb
├── base_input_object.rb
├── base_interface.rb
├── base_object.rb
├── base_scalar.rb
├── base_union.rb
├── mutation_type.rb
├── query_type.rb
In previous sections, I mentioned that GraphQL only has an endpoint; if you go to your routes file, you'll see something like this:
# config/routes.rb
Rails.application.routes.draw do
post "/graphql", to: "graphql#execute"
end
The endpoint is responsible for managing all our requests; note that this POST endpoint points to the graphql_controller and the execute action. In general, you can see that the controller processes all requests, context, variables, etc. and matches the types, either queries or mutations.
Creating the Object Types
It's time to create our first object types. As you saw previously, we have a type called object, and you can relate objects like a resource talking about REST API. In this case, user and movie are object types, and you can create them by running the following:
> rails generate graphql:object user
> rails generate graphql:object movie
These commands create the user and movie types within the graphql/types folder; this is the user type:
# app/graphql/types/user_type.rb
module Types
class UserType < Types::BaseObject
field :id, ID, null: false
field :email, String, null: true
field :first_name, String, null: true
field :last_name, String, null: true
field :created_at, GraphQL::Types::ISO8601DateTime, null: false
field :updated_at, GraphQL::Types::ISO8601DateTime, null: false
end
end
Each field is an attribute of the model, and we are defining the type for each one. For example, If we say that the user id is an ID type or that the user’s email is a string type, then you'll get an error if you send an integer for the email. The null option tells us which field needs to be present in the query.
We can also define custom fields; suppose that you want the number of movies for each user, you can add the following:
# app/graphql/types/user_type.rb
module Types
class UserType < Types::BaseObject
...
field :movies_count, Integer, null: true
def movies_count
object.movies.size
end
end
end
In these methods, the object refers to the Rails model, which is the user model in this case.
We can also refer to other types. For example, if we want to show a list of movies that each user has created, add this line:
# app/graphql/types/user_type.rb
module Types
class UserType < Types::BaseObject
...
field :movies_count, Integer, null: true
field :movies, [Types::MovieType], null: true
def movies_count
object.movies.size
end
end
end
As you can see, we are just adding an array of MovieType, and we can add an element by removing the brackets.
Creating Queries
There are two types of requests, query type and mutation type. Queries are all the requests you use to fetch data (using GET), Mutations are all the requests where you modify data (POST, PUT and DELETE). These types are defined in our schema:
# app/graphql/graphql_example_schema.rb
class GraphqlExampleSchema < GraphQL::Schema
mutation(Types::MutationType)
query(Types::QueryType)
...
So, let's create two queries; the first one retrieves all users, and the second one retrieves a user by providing his or her ID. To do so, open the query_type.rb file and add the following:
# app/graphql/types/query_type.rb
module Types
class QueryType < Types::BaseObject
# Get all users
field :users, [Types::UserType], null: false
def users
User.all
end
# Get a specific user
field :user, Types::UserType, null: false do
argument :id, ID, required: true
end
def user(id:)
User.find(id)
end
end
end
We have defined two fields, users and user, with their respective methods. The users field returns a users array and can't be null, while the user field accepts an id as the argument and is required; note that the id is an ID type and returns a single user object.
To test these queries, we need to use the graphiql tool, but first, it's necessary to add the following to our routes.rb file:
# config/routes
Rails.application.routes.draw do
if Rails.env.development?
mount GraphiQL::Rails::Engine, at: "/graphiql", graphql_path: "graphql#execute"
end
post "/graphql", to: "graphql#execute"
end
Before testing our queries in the development environment, open your config/application.rb and uncomment this line:
# config/application.rb
require "sprockets/railtie"
Sprockets is necessary at this point to compile and serve web assets for Graphiql, and finally, create this file: app/assets/config/manifest.js:
// app/assets/config/manifest.js
//= link graphiql/rails/application.css
//= link graphiql/rails/application.js
Run the server with rails s and go to localhost:3000/graphiql, and voila! You'll see Graphiql in action:
Next, let's add some users. To use the Faker gem to generate random data, open your db/seeds.rb file and add the following:
# db/seeds.rb
10.times do
user = User.create(
email: Faker::Internet.email,
first_name: Faker::Name.first_name,
last_name: Faker::Name.last_name
)
Movie.create(
user: user,
title: Faker::Movie.title,
year: Faker::Date.between(from: '2000-01-01', to: '2021-01-01').year,
genre: Faker::Book.genre
)
end
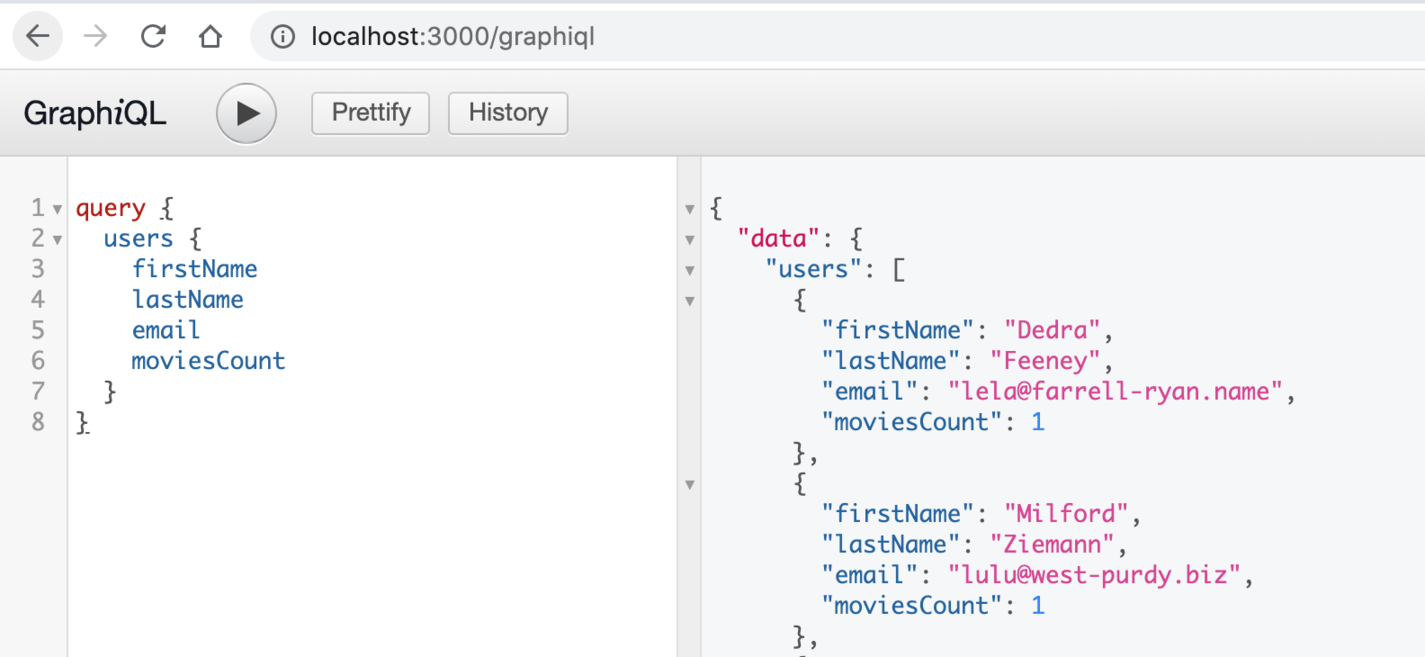
Don't forget to run rails db:seed to load our seed file, then you can paste the following code in the browser and click the play button to see the API working:
query {
users {
firstName
lastName
email
moviesCount
}
}
With this, you'll see a list of users defined in the users field. You can specify the user attributes you want and experiment with it:
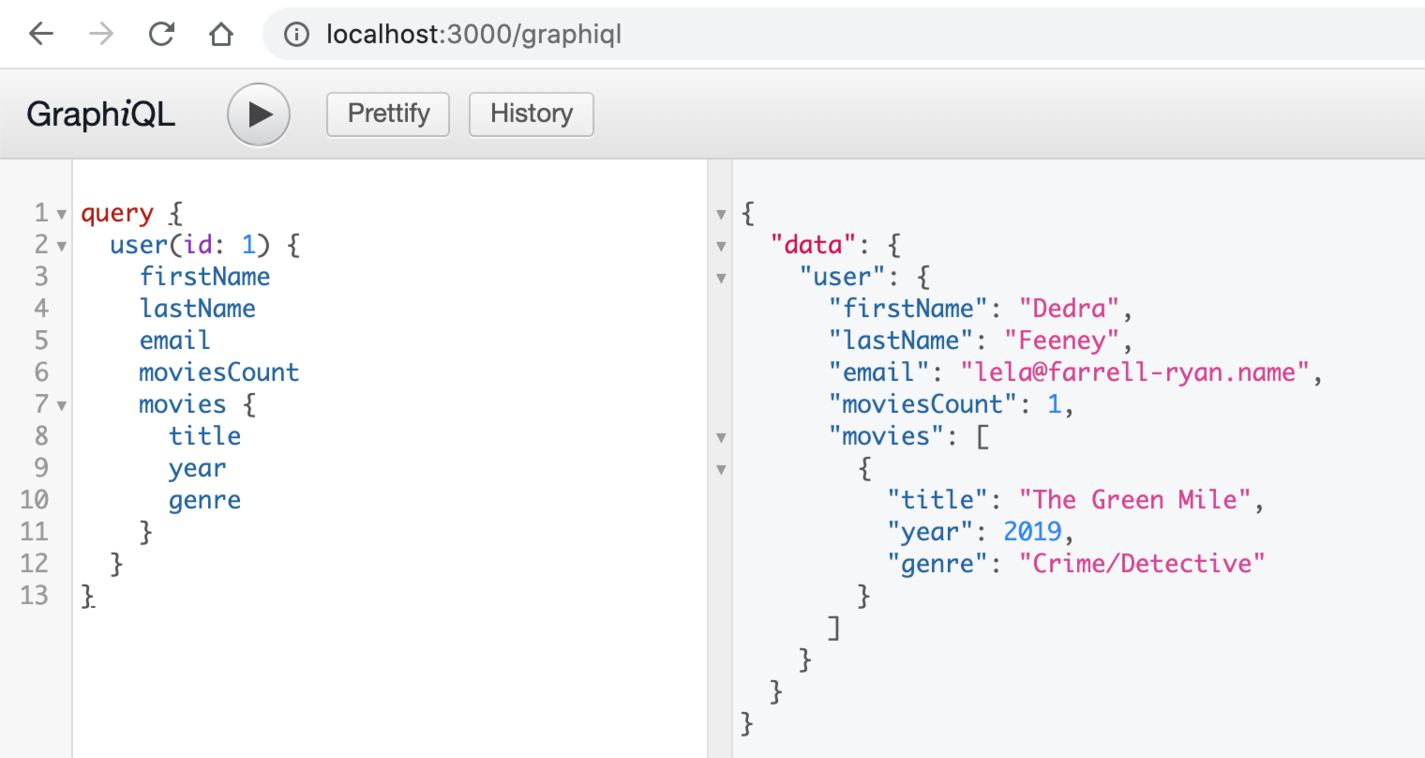
Now, you can run the following code to get a single user:
query {
user(id: 1) {
firstName
lastName
email
moviesCount
movies {
title
year
genre
}
}
}
Creating a Mutation
As we said previously, mutations allow us to create, modify, or delete data. We're going to make some users, and to do this, create a app/graphql/mutations/create_user.rb file with the following:
class Mutations::CreateUser < Mutations::BaseMutation
argument :first_name, String, required: true
argument :last_name, String, required: true
argument :email, String, required: true
field :user, Types::UserType, null: false
field :errors, [String], null: false
def resolve(first_name:, last_name:, email:)
user = User.new(first_name: first_name, last_name: last_name, email: email)
if user.save
{ user: user, errors: [] }
else
{ user: nil, errors: user.errors.full_messages }
end
end
end
We receive an argument to create the user, and you can set the type and whether it's required. We return a field, which, in this case, is the user or the errors. The resolve method receives the arguments as params, and it contains the logic to create the user.
Finally, add the mutation to the mutation_type.rb file to be used in the API:
# app/graphql/types/mutation_type.rb
module Types
class MutationType < Types::BaseObject
field :create_user, mutation: Mutations::CreateUser
end
end
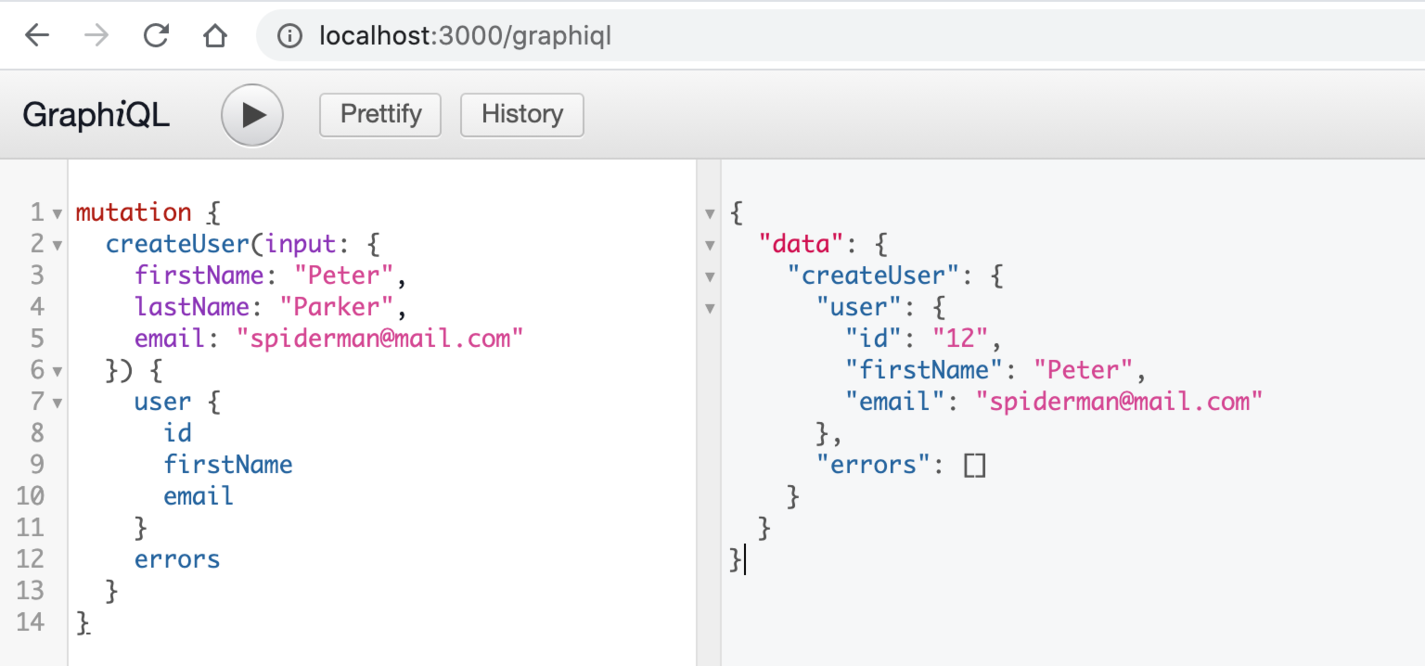
We are ready to test it, so go to the browser, paste the following code, and run it:
mutation {
createUser(input: {
firstName: "Peter",
lastName: "Parker",
email: "spiderman@mail.com"
}) {
user {
id
firstName
email
}
errors
}
}
It returns the created User! 🤟🏼
You are ready to create your own GraphQL API with Rails! 🎉
Considerations
- N+1 problems
Be careful when defining associations. They are now described at the runtime because your API is dynamic, so N+1 problems are more difficult to detect.
You can avoid them by using includes in your queries. For example, if you want to load the users with their respective movies and the movies with their actors (suppose you have an actors table for this example), you can do this:
User.includes(movies: :actors)
If you go to the Rails documentation you'll see the following: With includes, Active Record ensures that all of the specified associations are loaded using the minimum possible number of queries.
- Prevent deeply nested queries
Deeply nested queries can generate N+1 problems and add complexity, but we can prevent them by defining a variable at the schema level:
class MySchema < GraphQL::Schema
# ...
max_depth 10
end


