As a JavaScript developer, you work with text data all the time. However, computers don't naturally understand text in the same way as humans. Instead, text data must be converted into binary data, which computers can understand and manipulate. Character encoding is the process of mapping characters to binary data so that computers can work with text. Character encoding is important because it enables text to be stored and transmitted electronically. It is used in a wide range of applications, from web development to data storage and communication. For different computers and devices to work together, they must use the same encoding scheme. In the context of JavaScript development, character encoding is particularly important, as JavaScript is often used to manipulate and display text data in web applications.
In this comprehensive article, we will explore character encoding in JavaScript, including both Node.js and the browser side. We will start by providing an introduction to character encoding and the Unicode character encoding standard, which has become the de facto standard for encoding text data in modern computing. Next, we will take a closer look at ASCII encoding, the encoding standard that preceded Unicode, and how Unicode has largely replaced it. We will then dive into UTF-8 encoding, which is the most widely used character encoding standard in JavaScript and other modern programming languages. By the end of this article, you will have a solid understanding of character encoding in JavaScript and be equipped with the knowledge necessary to effectively work with text data in your JavaScript applications. Let's get started!
Understanding Unicode
Unicode is a character encoding standard developed to solve the problem of previous encoding schemes being unable to represent all characters in all languages. It provides a unique number, called a code point, for each character, symbol, and emoji in every language. Unicode has become the de facto standard for character encoding in modern computing and has largely replaced older encoding standards, such as ASCII. To work with Unicode in JavaScript, it's important to understand its structure and how it differs from other encoding standards.
ASCII encoding
The American Standard Code for Information Interchange (ASCII) was the first widely used character encoding standard. It was developed in the 1960s and based on the English alphabet and some common punctuation marks. However, ASCII had several limitations, including its inability to represent characters from other languages and limited character set. As a result, it has largely been replaced by Unicode. While you may not encounter ASCII much in your JavaScript development, it's important to be aware of its history and limitations to better understand how character encoding has evolved over time.
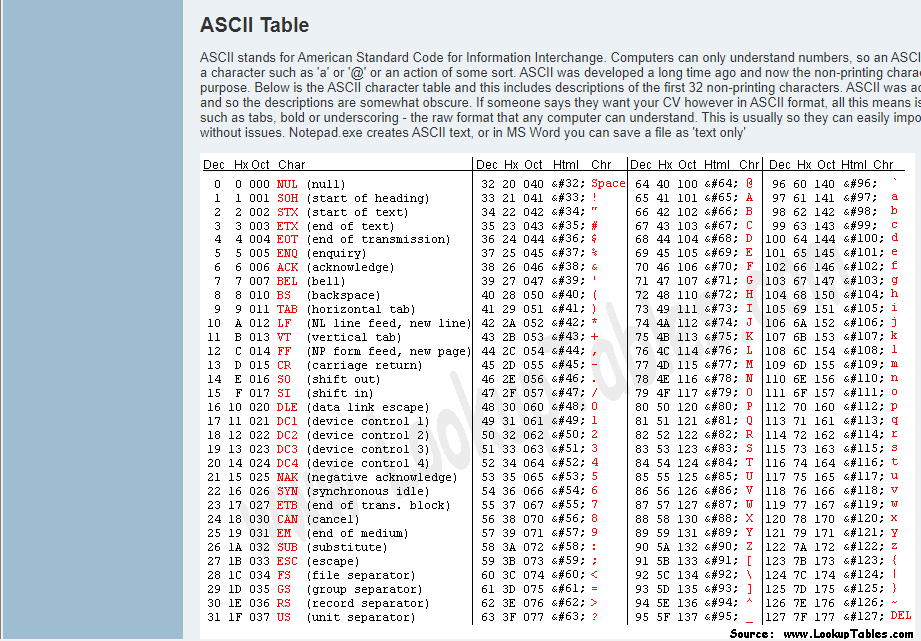 ASCII
ASCII
UTF-8 encoding
The character encoding standard UTF-8 is based on Unicode. It is the most widely used character encoding standard in modern computing, including in JavaScript. UTF-8 utilizes variable-length encoding, which means that it uses varying numbers of bytes to represent different characters. This allows it to represent all characters in all languages while being efficient in terms of storage and transmission. In JavaScript, UTF-8 is used to encode text data in strings and other data structures. Understanding how UTF-8 works is essential for working with text data in JavaScript applications.
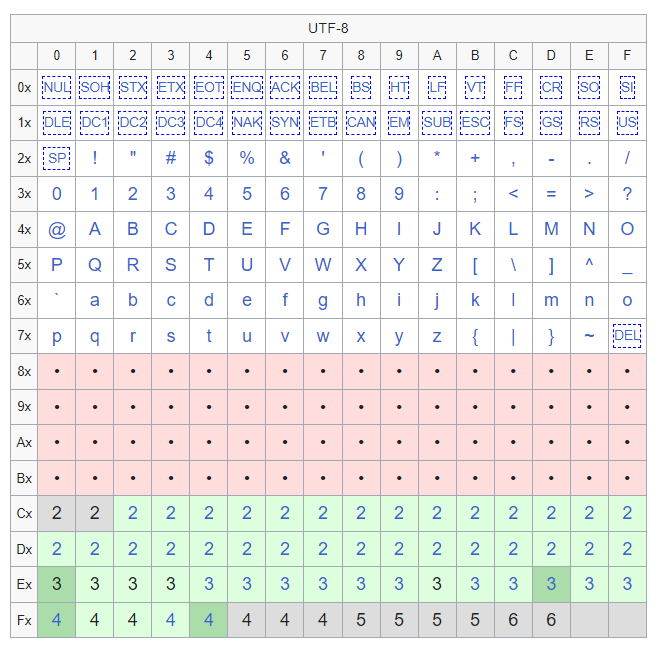 UTF-8
UTF-8
UTF-16 encoding
UTF-16 is another character encoding standard that is based on Unicode. It was designed to utilize fixed-length encoding, with each character represented by two bytes. While UTF-16 is still used in some applications, it is less common than UTF-8. One advantage of UTF-16 is that it is more efficient for some languages, such as Chinese and Japanese, which have a large number of characters. However, a disadvantage of UTF-16 is that it requires more storage space than UTF-8 for most text data. Additionally, some operating systems and applications don’t support UTF-16, which can cause compatibility issues. In JavaScript, UTF-16 is used in some contexts, such as when working with the DOM or certain APIs. However, UTF-8 is generally preferred for most text data.
It’s worth mentioning that in a web browser, character encoding is typically handled using the HTML meta tag. The meta tag is included in the head section of each HTML page to ensure that non-ASCII characters are displayed correctly.
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>My Web Page</title>
</head>
<body>
<p>こんにちは</p>
</body>
</html>
However, JavaScript can be used to dynamically load or generate content on a webpage, such as text or images. In these cases, it may be necessary to specify the type of character encoding for the dynamically generated content, which can’t be done with a meta tag.
const string = 'こんにちは、世界!'; // Japanese string
const encodedString = encodeURIComponent(string);
console.log(encodedString);
In this example, we start by creating a string variable called string that contains a Japanese greeting, "こんにちは、世界!", which means "Hello, world!" in English. We then use the encodeURIComponent() function to encode the string variable as a URI component using UTF-8 encoding. This function encodes each character in the string as a sequence of one to four bytes, depending on its Unicode code point. Finally, we log the encodedString variable to the console using the console.log() function, which will output the URI-encoded version of the original string to the console:
%E3%81%93%E3%82%93%E3%81%AB%E3%81%A1%E3%81%AF%E3%80%81%E4%B8%96%E7%95%8C%EF%BC%81
In this output, each non-ASCII character in the original string is represented as a sequence of percent-encoded bytes, which allows the string to be transmitted over the internet or stored in a database without losing any information. The % symbol is followed by the two-digit hexadecimal representation of each byte in the encoded sequence.
To decode a URI-encoded string in JavaScript, you can use the decodeURIComponent() function. It converts the percent-encoded bytes back into their original characters.
const decodedString = decodeURIComponent(encodedString);
console.log(decodedString);
In the code above, the variable encodedString contains the URI-encoded version of the Japanese greeting string. We use the decodeURIComponent() function to decode the percent-encoded bytes in encodedString back into their original characters using UTF-8 encoding. This function reverses the process of URI encoding and returns the decoded string. Finally, we log the decodedString variable to the console using the console.log() function, which will output the original Japanese greeting string:
こんにちは、世界!
In this output, the decoded string is identical to the original Japanese greeting that we started with, which confirms that the encoding and decoding process worked correctly.
Ajax requests
You can also send and receive data using AJAX. In this case, it's important to specify the character encoding used by the server. This can be done using the charset option of the Content-Type header:
const xhr = new XMLHttpRequest();
xhr.open('GET', '/data', true);
xhr.setRequestHeader('Content-Type', 'application/json; charset=utf-8');
xhr.onload = () => {
const data = JSON.parse(xhr.responseText);
console.log(data);
};
xhr.send();
Browser forms and cookies
Working with cookies and form data in a web browser also requires handling character encoding. Cookies should be URL-encoded to ensure that they can be properly transmitted and decoded by the server. Form data can be sent using either the GET or POST methods, and the character encoding should be specified using the enctype attribute of the form:
document.cookie = `name=${encodeURIComponent('John Doe')}; expires=${expires}; path=/`;
<form action="/submit" method="post" enctype="application/x-www-form-urlencoded">
<input type="text" name="name" value="John Doe">
<button type="submit">Submit</button>
</form>
Character encoding in Node.js
Node.js is a popular JavaScript runtime that allows you to build server-side applications using JavaScript. When working with text data in Node.js, it's important to understand how character encoding works. In Node.js, text data is typically represented as strings. However, in JavaScript, strings are encoded using the UTF-16 standard, which can cause issues when working with other character encodings. When reading and writing text files in Node.js, you can specify the type of character encoding using the fs module. For example, to read a file as UTF-8, you can use the following code:
const fs = require('fs');
fs.readFile('myfile.txt', 'utf-8', (err, data) => {
if (err) throw err;
console.log(data);
});
In the code above, we are using the Node.js built-in module fs, which stands for "file system", to read the contents of a file called myfile.txt. We start by importing the fs module using the require function and assigning it to a variable called fs. Then, we use the readFile method provided by the fs module to read the content of myfile.txt. This method takes three arguments: the path to the file to be read (in this case, myfile.txt), the encoding to be used to read the file (in this case, 'utf-8'), and a callback function to be called when the file has been read.
The callback function takes two parameters: an err parameter, which contains an error object if an error occurred while reading the file, and a data parameter, which contains the content of the file as a string if the file was successfully read. In the callback function, we first check if an error occurred while reading the file by checking whether the err parameter is null. If an error occurred, we throw the error object; otherwise, we log the content of the file to the console using the console.log function.
When working with HTTP requests and responses in Node.js, you can also specify the type of character encoding using the Content-Type header. For example, to send a response as UTF-8, you can use the following code:
const http = require('http');
http.createServer((req, res) => {
res.writeHead(200, { 'Content-Type': 'text/html; charset=utf-8' });
res.write('Hello, 世界!');
res.end();
}).listen(3000);
The code above sends a response: ‘Hello’. Note that in the Content-Type header, we specify the character encoding of the response.
When working with databases in Node.js, you may also need to specify the character encoding for the connection. For example, when using the mysql module, you can specify the character encoding in the connection options:
const mysql = require('mysql');
const connection = mysql.createConnection({
host: 'localhost',
user: 'me',
password: 'secret',
database: 'mydb',
charset: 'utf8mb4' //we specify the character encoding for the mysql connection here
});
connection.connect();
Finally, it's important to be aware of character encoding errors in Node.js. When working with text data, it's possible to encounter errors due to incorrect encoding or malformed data. To handle these errors, you can use the iconv-lite module, which provides utilities for encoding and decoding text data:
const iconv = require('iconv-lite');
const buf = iconv.encode('Hello, world!', 'utf-8');
const str = iconv.decode(buf, 'utf-8');
console.log(str); // Output: Hello, world!
In the code above, we are using the iconv-lite library to encode and decode a string using the utf-8 character encoding. First, we import the iconv-lite library using the require function and assign it to a variable called iconv. Then, we create a new Buffer object called buf by encoding the string 'Hello, world!' using the utf-8 encoding with the iconv.encode function. Next, we create a new string called str by decoding the buf buffer using the utf-8 encoding with the iconv.decode function. Finally, we log the str string to the console using the console.log function.
Best practices for character encoding
When working with character encoding in JavaScript, there are a few best practices to keep in mind:
- Use UTF-8 encoding for all text data. This is the most widely used and compatible encoding standard, and it ensures that your data can be properly read and displayed across various platforms and languages.
- Avoid using non-ASCII characters in variable and function names. While this is technically allowed in JavaScript, it can cause encoding mismatches and make your code harder to read and understand.
- When concatenating strings, always use the
+operator or template literals (${}) instead of the+=operator. This can prevent encoding mismatches and ensure that your code works correctly with non-ASCII characters. - When handling user input, always validate and sanitize the data to prevent encoding attacks and other security vulnerabilities. This can be done using, for example, the OWASP ESAPI or DOMPurify library.
- When working with external APIs or databases, always verify the expected character encoding and convert your data to UTF-8 if necessary. This can prevent encoding mismatches and ensure that your data is properly stored and retrieved.
Debugging character encoding issues
Debugging character encoding issues can be tricky, but several techniques can be used to identify and fix these issues. One common issue is encoding mismatches, where data is encoded in one format but decoded in another. This can lead to garbled or corrupted data and may be difficult to identify.
One approach to debugging encoding issues is to use a tool like the UTF-8 Validator, which can help identify common issues with encoding. Additionally, you can use console.log statements to output the encoded and decoded data, and then compare them to see if there are any differences. Another helpful technique is to use a tool like the iconv library, which can convert data between different character encodings. This can be particularly helpful when working with data from external sources that may use a different encoding than your application.
Conclusion and further reading
In this article, we've covered the basics of character encoding in JavaScript, including the different encoding standards, how they work, and how to work with them in Node.js and web browsers. We've also covered some best practices for working with character encoding in JavaScript and provided tips and techniques for debugging encoding issues. If you want to learn more about character encoding in JavaScript, there are several resources. The Unicode Consortium's website provides detailed information about the Unicode standard, while the Mozilla Developer Network has extensive documentation on character encoding in JavaScript. Additionally, there are several books on JavaScript that cover this topic in depth, such as "JavaScript: The Definitive Guide" by David Flanagan and "Eloquent JavaScript" by Marijn Haverbeke.


