Ditching your single page app for...turbolinks?
Turbolinks - it's probably one of the most despised words in the Rails universe.
Maybe you tried it out. You included turbolinks in new project or an existing app. And soon enough the app began to fail in strange and wonderful ways. Good thing the fix was just as easy - turn off turbolinks.
...but some companies make it work. Here at Honeybadger, we've made it work - and we're no geniuses.
The answer is so simple that I'm almost hesitant to bring it up. But after giving talks on this subject at Ruby Nation and Madison+Ruby, it appears that people do find this topic helpful. So let's dig in.
How Turbolinks and PJAX work
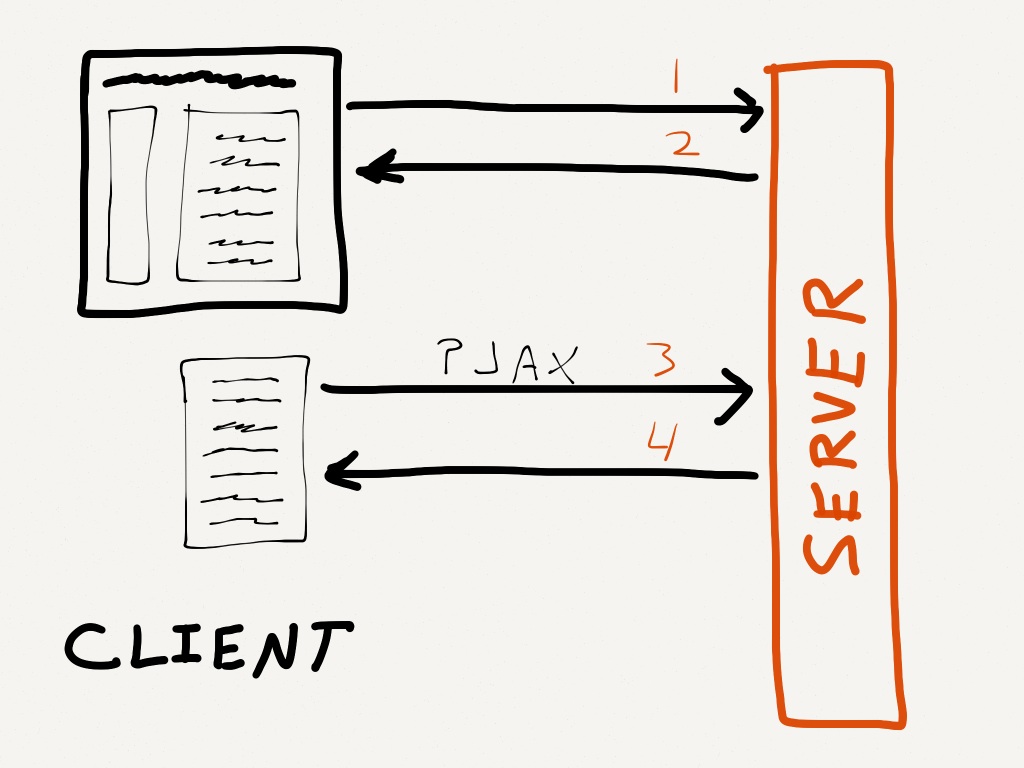
Turbolinks and PJAX work in essentially the same way. They're so similar, I'm going to just say PJAX from now on. :)
You can understand PJAX in terms of two page requests. The first time a user requests a page, it's served just like any other "traditional" Rails page. But when the user clicks on a PJAX-enabled link, something special happens. Instead of completely reloading the page, only a portion of the page is updated. It's done via AJAX.
This gives us a lot of the advantages of a single page app, while sidestepping some of the difficulties:
- PJAX apps often seem just as snappy as single page apps, since the page no longer has to be completely reloaded on every request.
- You get to use the same stack for front-end and back end development
- PJAX apps degrade gracefully by default when the user has disabled JS
- PJAX apps are more easily made accessible and SEO friendly
Implementing Turbolinks
There are lots of libraries that will do the heavy lifting of PJAX for you. Turbolinks is probably the most well-known. Setting it up is just a matter of including the turbolinks gem in your Gemfile:
gem 'turbolinks'
...and including the JS in app/assets/javascripts/application.js
//= require turbolinks
Now when you reload your app, every internal link will be a turbolink. When you click on them, the new page will be requested via AJAX and inserted into the current document.
Implementing jquery-pjax
Here at Honeybadger, we use a PJAX library that was originally developed by Github. It requires a little more configuration than Turbolinks, but it's also quite a bit more flexible.
Instead of assuming that all links are PJAX, it lets you control that. It also lets you control where on the page the PJAX content will be inserted.
The first thing I need to do is add a container to my HTML
<div class="container" id="pjax-container">
Go to <a href="/page/2">next page</a>.
</div>
Now I need to set up the PJAX link:
$(document).pjax('a', '#pjax-container')
Finally, I'll tell rails not to render the layout on PJAX requests. You have to do something like this, or you'll wind up with duplicate headers and footers. ie. your website will look like Inception.
def index
if request.headers['X-PJAX']
render :layout => false
end
end
It's not that easy!
Ok, it's a little more complicated than I've let on. Mostly because of one giant pitfall that very few people talk about.
When your DOM doesn't get cleared on every page load, it means that JS that may have worked on your traditional Rails app now breaks in very strange ways.
The reason for this is that many of us learned to write JS in a way that encouraged accidental naming conflicts. One of the most insidious culprits is the simple jquery selector.
// I may look innocent, but I'm not!
$(".something")
Writing JS for pages that don't reload
Conflicts are the number one problem when you write JS for pages that never reload. Some of the weirdest, hard to debug problems occur when JS manipulates HTML that it was never meant to touch. For example, let's look at an ordinary jQuery event handler:
$(document).on("click", ".hide-form", function() {
$(".the-form").hide();
});
This is perfectly reasonable, if it only runs on one page. But if the DOM never gets reloaded, it's only a matter of time before someone comes along and adds another element with a class of .hide-form. Now you have a conflict.
Conflicts like this happen when you have a lot of global references. And how do you reduce the number of global references? You use namespaces.
Namespacing Selectors
In the Ruby class below, we're using one global name - the class name - to hide lots of method names.
# One global name hides two method names
class MyClass
def method1
end
def method2
end
end
While there's no built-in support for namespacing DOM elements (at least not until ES6 WebComponents arrive) it is possible to simulate namespaces with coding conventions.
For example, imagine that you wanted to implement a tag editing widget. Without namespacing, it might look something like this. Note that there are three global references.
// <input class="tags" type="text" />
// <button class="tag-submit">Save</button>
// <span class="tag-status"></span>
$(".tag-submit").click(function(){
save($(".tags").val());
$(".tag-status").html("Tags were saved");
});
However, by creating a "namespace" and making all element lookups relative to it, we can reduce the number of global references to one. We've also gotten rid of several classes altogether.
// <div class="tags-component">
// <input type="text" />
// <button>Save</button>
// <span></span>
// </div>
$container = $("#tags-component")
$container.on("click", "button" function(){
save($container.find("input").val());
$container.find("span").html("Tags were saved");
});
I told you it was simple.
In the example above, I namespaced my DOM elements by putting them inside of a container with a class of "tags-component." There's nothing special about that particular name. But if I were to adopt a naming convention where every namespace container has a class ending in "-component" some very interesting things happen.
You can recognize incorrect global selectors at a glance.
If the only global selectors you allow are to components, and all components have a class ending in "-component" then you can see at a glance if you have any bad global selectors.
// Bad
$(".foo").blah()
// Ok
$(".foo-component".blah()
It becomes easy to find the JS that controls the HTML
Let's revisit our interactive tag form. You've written the HTML for the form. Now you need to add some JS and CSS. But where do you put those files? Luckily, when you have a naming scheme for namespaces, it translates easily to a naming scheme for JS and CSS files. Here's what the directory tree might look like.
.
├── javascripts
| ├── application.coffee
│ └── components
│ └── tags.coffee
└── stylesheets
├── application.scss
└── components
└── tags.scss
Automatic initialization
In a traditional web app, it's normal to initialize all your JS on page load. But with PJAX and Turbolinks, you have elements being added and removed from the DOM all the time. Because of this, it's really beneficial if your code can automatically detect when new components enter the dom, and initialize whatever JS is needed for them on the fly.
A consistent naming scheme, makes this really easy to do. There are countless approaches you might take to auto-initialization. Here's one:
Initializers = {
tags: function(el){
$(el).on("click", "button", function(){
// setup component
});
}
// Other initializers can go here
}
// Handler called on every normal and pjax page load
$(document).on("load, pjax:load", function(){
for(var key in Initializers){
$("." + key + "-component").each(Initializers[key]);
}
}
It makes your CSS better too!
JavaScript isn't the only source of conflicts on a web page. CSS can be even worse! Fortunately, our nifty namespacing system also makes it much easier to write CSS without conflicts. It's even nicer in SCSS:
.tags-component {
input { ... }
button { ... }
span { ... }
}

Written by
Starr HorneStarr Horne is a Rubyist and former Chief JavaScripter at Honeybadger. When she's not fixing bugs, she enjoys making furniture with traditional hand-tools, reading history and brewing beer in her garage in Seattle.